This article also has a Chinese version.
This series of articles mainly records my attempt to implement a Hypervisor using Rust. The table of contents:
- Mini VMM in Rust - Basic
- Mini VMM in Rust - Mode Switch
- Mini VMM in Rust - Run Real Linux Kernel
- Mini VMM in Rust - Implement Virtio Devices
This article is the fourth in the series. It will cover implementing a Virtio Queue and virtio-net from scratch and using TAP as the backend for a virtio-net device. To better assemble these components, additional components such as a Bus and EventLoop will also be added.
During this experiment, I also contributed some PRs to firecracker and cloud-hypervisor, please refer to the end of the article.
There is a lot of code in the article, please use the directory navigation on the right when necessary.
The previous three articles were completed in the second half of 2022, while this chapter and the corresponding experimental code have been in draft form until recently (now it is 2024). Over a few weekends, I added some code and completed this article.
The next article may support PCI devices and direct I/O for VF devices if I have the time(but don’t expect it, haha).
Introduction to Virtio
For a reference to Virtio, see the official documentation version 1.1 (version 1.0 is also usable): https://docs.oasis-open.org/virtio/virtio/v1.1/csprd01/virtio-v1.1-csprd01.html.
In full virtualization mode, I/O operations attempted by the guest can trigger VM_EXIT, interrupting the ongoing context of the VM and leading to significant context-switching overhead.
Virtio is a standard for virtualizing devices. When both host and guest adhere to this standard, I/O requests and responses can be handled via shared memory, greatly reducing context switches and enhancing I/O performance. Since it requires cooperation from the guest, it is known as paravirtualization.
In addition to optimizing performance through shared memory, other high-performance I/O strategies exist, such as hardware-supported virtualization (SR-IOV), which allows a single physical device to be virtualized into multiple Virtual Functions. This architecture permits individual Functions to be dedicated to VMs (this requires IOMMU support for address translation).
Virtio implementation is typically supported by kernel drivers in the Guest and handled by VMM developers in the Host. Sometimes, for better performance, the Host implementations could be kernel-based (vhost—saving on context switches between user and kernel space and utilizing hardware instructions that are not accessible in user space) or a standalone process (vhost-user—segregating unrelated logic from the VMM code and refining process permissions). It can even be hardware-supported (vDPA).
Both Windows and Linux have virtio drivers (e.g., virtio-net, virtio-blk in Linux), enabling optimized I/O performance when the VMM supports virtio while running within VMs.
A Virtio device consists of five components:
The Device Status Field represents the status of the device; Feature Bits are used for feature negotiation; Configuration Space is for parameters that change infrequently or are specific to initialization (e.g., number of pages for a Balloon device), or unique information about the device; Virtqueues facilitate data transfer (a device can have zero or more virtqueues); Notifications are divided into two main categories: ring notifications (about available and used buffers) and config space notifications.
How does bidirectional notification work? Guests notifying the Host is commonly referred to as a “kick” Typically, this utilizes KVM’s ioeventfd capability. When the Guest writes a specific value to a designated MMIO/PIO address, it triggers an EPT misconfiguration exception. KVM handles this exception and converts it into an eventfd write to notify the Host (though it could also be achieved using VM_EXIT, the performance is generally poorer in comparison). As previously mentioned, the Host notifies the Guest by injecting interrupts, which can be controlled using irqfd.
Data Flow
Handshake
Virtio can operate over MMIO or PCI (there’s also a channel IO version for S390 platforms). PCI interface supports device hot-plugging and conveniently maps physical devices directly into VMs, adding substantial complexity to theimplementation (a comparison on LWN notes that in qemu, virtio-MMIO is implemented in a single file with 421 lines of code, while virtio-PCI spans 24 files with 8952 lines, more than 20 times that of virtio-MMIO). Complex implementations increase the attack surface and can potentially slow down the driver.
As we aim to implement a fully functional yet basic VMM with no substantial physical device mapping requirements, we will use MMIO.
The device needs to be discovered by the Guest and successfully handshake to be usable. Device initialization follows this order:
The driver MUST follow this sequence to initialize a device:
- Reset the device.
- Set the ACKNOWLEDGE status bit: the guest OS has notice the device.
- Set the DRIVER status bit: the guest OS knows how to drive the device.
- Read device feature bits, and write the subset of feature bits understood by the OS and driver to the device. During this step the driver MAY read (but MUST NOT write) the device-specific configuration fields to check that it can support the device before accepting it.
- Set the FEATURES_OK status bit. The driver MUST NOT accept new feature bits after this step.
- Re-read device status to ensure the FEATURES_OK bit is still set: otherwise, the device does not support our subset of features and the device is unusable.
- Perform device-specific setup, including discovery of virtqueues for the device, optional per-bus setup, reading and possibly writing the device’s virtio configuration space, and population of virtqueues.
- Set the DRIVER_OK status bit. At this point the device is “live”.
If any of these steps go irrecoverably wrong, the driver SHOULD set the FAILED status bit to indicate that it has given up on the device (it can reset the device later to restart if desired). The driver MUST NOT continue initialization in that case.
The driver MUST NOT notify the device before setting DRIVER_OK.
Device initialization and state changes are initiated by the Guest/Driver side. Therefore, in the VMM/Device context, it is only necessary to handle the corresponding events.
Under the PCI protocol, its mechanisms can be used to achieve device discovery. For MMIO, there are no corresponding mechanisms, but devices can be made discoverable to Linux by inserting a device description into the boot cmdline.
For example, inserting virtio_mmio.device=4K@0xd0000000:5 indicates that there is a virtio device based on MMIO with the start address of the MMIO region at 0xd0000000, a length of 4K, and an irq of 5.
The device operates agreed actions by reading and writing specific offsets within the MMIO address range. For instance, at Offset = 0, only reading is allowed, and it must return 0x74726976 (the ASCII little endian representation of “virt”); at Offset = 0x10, it’s read-only, and the Device should return its supported features; at Offset = 0x14, it’s write-only, where the chosen features are written into the Device.
Once the Guest discovers the device, it can choose an appropriate moment to perform the initialization logic. The order of state changes has already been clearly stated in the earlier documentation and needs no further elaboration.
The device needs to support these read and write operations, but as the processing of these operations is quite similar between devices, it’s possible to abstract a Wrapper(or Adapter if you like) structure, which could be named MMIOTransport. This structure wraps the specific device implementation and stores some necessary information for the handshake process (such as queue_select), converting MMIO read/write operations into operations on its own fields and the underlying device. Specific device implementations also need to be somewhat abstracted, exposing a general interface for MMIOTransport to invoke.
Communication
During the handshake:
- All reads and writes are processed by the vCPU emulation thread after triggering a VM_EXIT through writing to MMIO.
After the handshake is complete, when the Guest wants to send data:
- [Guest] Fetches a Descriptor Chain from the Used Ring and writes data into the buffer it points to.
- [Guest] The Descriptor index (if it’s a chain of multiple Descriptors, only the index of the first one is needed) is then written into the Available Ring, and the index on the Available Ring is updated.
- [Guest] The Guest needs to notify the Host to consume the data, which is triggered either through PCI or by writing to MMIO, detected by KVM.
- [Host Kernel] Upon detection by KVM, the corresponding IoEventFd pre-registered on the VMM side is notified.
- [Host User] Upon receiving the notification, the VMM consumes the Available Ring, retrieves the Descriptor Table Index, processes the data in the buffer (for example, forwarding it to a network card), and afterwards places the Descriptor Table Index back into the Used Ring.
- [Host User] After writing into the Used Ring, it is necessary to notify the Guest to process the data through IrqFd.
When the Host wants to send data to the Guest:
- [Host User] Retrieves a Descriptor Chain from the Available Ring and writes data into the buffer it points to.
- [Host User] The Descriptor index (and the total length of the data if it’s a chain of multiple Descriptors, only the index of the first one is needed) is then written into the Used Ring, and the index on the Used Ring is updated.
- [Host User] Needs to notify the Guest to consume the data, this is done via IrqFd.
- [Host Kernel] After the VMM writes to the eventfd, KVM injects an interrupt associated with it into the virtual machine.
- [Guest] Upon receiving the interrupt, the Guest driver consumes the Used Ring, retrieves the Descriptor Table Index and the length of the data, and reads the desired data.
- [Guest] After reading, it needs to place the Descriptor Table Index back into the Available Ring.
This detailed explanation delineates the sequence of actions required for bidirectional communication between the Guest and Host in a system utilizing MMIO for virtual device interactions.
Implementation
To implement a virtio device, you need to develop several components:
Virtio Queue: Used for unidirectional communication (for devices requiring bidirectional communication, two queues can be utilized).
MMIO/PCI Transport: Manages feature negotiation, status retrieval and changes, configuration reading and writing, etc.
Virtio Device: The specific implementation of the virtio device, such as virtio-net, virtio-blk, etc.
Virtio Queue
The Virtio Queue is the essence of virtio, defining the usage of shared memory. Virtio currently has three versions (1.0, 1.1, and 1.2, with earlier versions known as legacy). Versions 1.1 and later even differentiate between Split and Packed types, but for simplicity, we will only discuss the Split version.
A virtqueue consists of three parts:
1 | // ref: https://wiki.osdev.org/Virtio |
Inputs
- Descriptor Table is responsible for storing multiple Descriptors; a corresponding Descriptor can be accessed via its index. Each Descriptor contains a buffer pointer (GPA) and length, as well as the index of the next Descriptor in the chain.
- Available Ring stores multiple Descriptor Indexes and a Ring Index (indicating the next position for writing). The Guest writes to the Available Ring, while the Host only reads from it.
- Used Ring stores multiple Descriptor Indexes along with the total length of data written for each Descriptor, and a Ring Index (indicating the next position for writing). The Guest only reads from the Used Ring, while the Host only writes to it.
Descriptor Chain
How to describe a Descriptor Chain? A Descriptor stores the Next Descriptor index, so by additionally storing the Descriptor Table address and memory address mapping, this structure can autonomously retrieve the next Descriptor.
The memory address mapping is stored as a generic type M, which can be either an owned type or a reference type. There are generally three ways we use M: one is for temporary use, where passing &M and constraining M: GuestMemory suffices (auto deref will occur); another is for consuming M to construct a structure that holds M and needs to operate on M, similar to Queue::pop<M>, where passing M and constraining M: Deref<Target = impl GuestMemory> is required (manual deref); the last is for constructing a structure that holds M without consuming it, such as DescriptorChain::<M>::next, which compared to the previous usage, requires an additional constraint M: Clone. It is important to pay attention to the type of M being used; if M corresponds to an ownership type, then the cost of cloning might be significant, and it is necessary to consider whether this meets expectations. If it is expected that M should definitely be a reference type or another type that can be copied cheaply, the previous Clone constraint can be changed to a Copy constraint.
Additionally, storing the queue size to check if the index is valid and storing the current index for retrieval is necessary.
1 | pub struct DescriptorChain<M> { |
This allows us to leverage the DescriptorChain structure to solve the problem of loading the next Descriptor. Subsequently, we need to implement push/pop methods for the Queue to read and write the DescriptorChain.
Queue Definition
First, we need to define the Queue struct. What information should the Queue store?
- The memory of the Queue is managed by the Guest, so the Device side implementation only needs to record the memory addresses of these three items;
- To store the per-Queue information set during the handshake, it is also necessary to include corresponding fields in the Queue, including size and ready;
- Record the current read and write indices (next_avail, next_used), as well as the current batch write count (num_added);
- Store information obtained through initial values or feature negotiation during the handshake, including max_size and noti_suppres (noti_suppres indicates the
VIRTIO_F_EVENT_IDXfeature).
1 | pub struct Queue { |
Interrupt Suppression
It is necessary to introduce the VIRTIO_F_EVENT_IDX feature.
In implementations that do not support this feature, after writing messages (which could be multiple), it is necessary to notify the counterpart to consume them, as the counterpart cannot detect local memory writes. All communications based on shared memory require either busy-waiting or some form of notification mechanism. However, notifications are costly, and to minimize the number of notifications while avoiding delays, this feature was designed.
Once this feature is successfully negotiated, for the device, it only needs to notify when the counterpart completes writing to the AvailableRing at the index specified by UsedRing.AvailEvent; and it only notifies the counterpart when the local side writes to the UsedRing at the index specified by AvailableRing.EventIndex (the variable naming here corresponds to the previous C language definitions).
With this feature enabled, special attention must be paid to memory visibility issues. Inserting appropriate memory barriers can ensure consistency.
Moreover, once VIRTIO_F_EVENT_IDX is enabled, it implies that all events must be consumed at once (or consumed subsequently through an internally triggered callback). This is because there will be no further notifications from the counterpart, similar to handling epoll ET—either consume all at once or record readiness and trigger fd consumption by an internally generated signal.
Queue Pop
The implementation of pop includes two tasks:
- Detecting when there are messages available for consumption.
- Retrieving messages from the Queue.
Task 2 is quite straightforward; it simply involves reading the data corresponding to the next_avail index in the Descriptor Table. Since it must ensure that an element is present, let’s name this function pop_unchecked.
1 | impl Queue { |
So, how do we determine if there are messages available for consumption? It’s simple: just check if the AvailableRing index is greater than next_avail, right? We implement a function to read the AvailableRing index and based on this, we implement the len function:
1 | impl Queue { |
When .len() > 0, then pop_unchecked works for cases where VIRTIO_F_EVENT_IDX is not negotiated. However, when this feature is enabled, the following steps are necessary:
- Attempt to get the length; if
len > 0, read and return the data directly. - Write to
UsedRing.AvailEventto notify the Guest that new data is available and to inform the Device. - Attempt to read the length again.
Why is there a need to try again? As mentioned earlier, when VIRTIO_F_EVENT_IDX is enabled, all messages must be consumed in one go. If the producer thinks there is no need to trigger an event, and the consumer stops partway, it can lead to a situation where messages are left unprocessed, causing a hanging.
We define the reading of len by the Host Device as Event 1, and the update of UsedRing.AvailEvent by the Host Device as Event 2; the update of len by the Guest Driver as Event A, and the reading of UsedRing.AvailEvent by the Guest Driver as Event B. Thus, Events 1 and 2 are sequentially guaranteed, as are Events A and B. This leads to several possible sequences:
- A12B/A1B2/AB12: All involve updating
lenbefore reading it, ensuring no messages are missed; - 1A2B/12AB: The Device reads
lenfirst and finds no messages, assuming the process is complete, but the Driver successfully reads the latestAvailEvent. Although consumption stops, it will be correctly triggered by the next notification, so no messages are missed; - 1AB2: In this case, the Device thinks there are no messages to consume, but the Guest later generates a new message and reads the
AvailEvent(finding it unchanged). Finally, the Device updates theAvailEventand exits the processing flow. Clearly, the Device neither consumes all messages nor ensures the correct setting ofAvailEvent, leading to missed messages.
To solve this problem, we attempt to read messages again after updating the AvailEvent. This ensures continued consumption in case 3.
To access the latest len, we first add an Acquire fence during Pop to ensure visibility of the memory writes made before the writer’s Release fence; after writing to the AvailEvent, to make it visible post-reader’s Acquire fence, a Release fence is necessary. At the same time, we still need to access the current latest len, so we use an AcqRel fence.
1 | impl Queue { |
Queue Push
On the Device side, Queue Push only requires writing the message into the Used Ring. Since the Descriptor Index is always retrieved from the Available Ring, and the sizes of the Available Ring, Used Ring, and Descriptor Table are consistent, there is guaranteed to be space available for writing.
1 | impl Queue { |
This implementation is not difficult; it simply involves calculating the address and writing data in the C memory layout directly to it. It is important to ensure that the data is fully written before updating the Ring Index; therefore, a Release fence should be used before updating the Ring Index.
After the data is written and the Ring Index is updated, it is necessary to notify the peer. The status of the VIRTIO_F_EVENT_IDX feature must also be considered:
- When VIRTIO_F_EVENT_IDX is not enabled, it is mandatory to notify the peer after batch writing is complete.
- There is an exception here: do not notify the peer when the flag is set to 1 (the flag can only be 0 or 1).
- When VIRTIO_F_EVENT_IDX is enabled, notification is only necessary after writing data to a specific Index.
Therefore, a prepare_notify function can be implemented, and the device is responsible for notification when this function returns true.
1 | impl Queue { |
由于需要保证先前的内存写入与 Ring Index 更新的可见性,又需要保证后面读 used_event 的可见性,所以这里使用 AcqRel fence。最后计算是否需要 notify 的表达式很巧妙,参考了 kernel driver 侧的实现,它低成本地正确处理了 wrap 时的情况。
To ensure the visibility of previous memory writes and the update of the Ring Index, as well as the subsequent visibility of reading used_event, an AcqRel fence is used here. The formula for determining whether a notification is needed is quite clever, refering from the implementation on the kernel driver side, which handles wrap-around situations efficiently and correctly.
Queue Validate
Since both reading and writing to the Queue are performance-critical paths, and the sizes and addresses of the two Rings and the Descriptor Table are fixed after a successful handshake, it is beneficial to perform validity checks on these parameters in advance to ensure their memory layout and length are correct for subsequent operations.
Based on the documentation, the memory layout for the three components should be validated as follows:
- Descriptor Table should be 16-byte aligned, with a size of
16 * (Queue Size). - Available Ring should be 2-byte aligned, with a size of
6 + 2 * (Queue Size). - Used Ring should be 4-byte aligned, with a size of
6 + 8 * (Queue Size).
Additionally, since MMIO writes directly manipulate the size, the validity of the size written needs to be checked:
- The size must be a power of 2.
- The maximum size is 32768.
Finally, the device status must be verified as ready by reading and writing through the offset 0x044.
These checks ensure that the Queue’s memory structures are correct.
1 | impl Queue { |
MMIO Transport
All virtio devices require feature negotiation, state management, and config space operations, and besides MMIO, they may also need to support PCI (with roughly similar operational semantics). A good design is to abstract the access to virtio devices into a trait and write an Adaptor (i.e., Transport) to connect it to MMIO or PCI access.
The interface design for virtio devices depends on the transport access. MMIOTransport needs to implement responses to specific MMIO offset reads and writes according to the document 4.2.2 MMIO Device Register Layout.
Here, I directly copied the interface from Firecracker (with very minor changes):
1 | // Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved. |
MMIOTransport needs to hold a specific device in order to access it via the VirtioDevice interface; additionally, it needs to record some necessary states during feature negotiation and handshake. The implementation here also needs to follow the document mentioned earlier.
Here, I still copied the code from Firecracker (also with very minor changes):
1 |
|
Virtio-net Impl
Virtio-net includes two virtio queues for bidirectional communication.
How should we handle the packets read and written by virtio-net? Virtio-net targets layer 2 packets, and one implementation is to create a TAP device (which also operates at layer 2), and then connect the virtio-net’s tx and rx to this TAP device.
How can we use the TAP device to allow the VM to access networks outside the host?
- One method is to assign an address and subnet to the TAP, and set the VM’s IP as another address in that subnet; then use iptables to perform NAT, with forwarding by the host kernel.
- Another method is to bridge the TAP with an outgoing network card (such as eth0) and configure the same segment IP inside the VM.
Define the Net structure (including the TAP device, two queues, their respective ioeventfds, device-bound irqfds, features, and status):
1 | const NET_NUM_QUEUES: usize = 2; |
After the handshake, MMIOTransport calls activate to notify that the device is ready. The handling of this event involves registering callbacks for processing tx, rx, and tap to the main thread’s epoll. This way, when an event occurs (tx/rx ready, or tap read/write ready), it can trigger the Net device to perform the relay action.
Implementing relay is not difficult; the simplest method is to maintain a buffer, reading from one side and writing to the other. However, since the Descriptor Chain is essentially equivalent to [iovec], we can define a conversion trait to transform the Descriptor Chain into [iovec] at low cost. This allows us to directly use readv/writev and avoid additional copying overhead (here, the design involves passing in &mut Vec, expecting the caller to manage it to avoid frequent allocation overhead of Vec):
1 | pub trait IntoIoVec { |
Another issue is state management. The tx and rx queues can be considered as edge-triggered (regardless of whether they are registered as ET/LT on epoll, as long as VIRTIO_F_EVENT_IDX is negotiated, it behaves as edge-triggered, and under normal implementation, it requires consuming to empty to receive the next notification). Therefore, it is necessary to consider whether the tap fd should focus on edge-triggered or level-triggered. Typically, using edge-triggered and recording the state is more efficient. There is also a background here, which is that the TUN/TAP device is always writable (according to the documentation, the kernel will silently drop when the buffer is full, which can be confirmed by observing the SKB_DROP_REASON_FULL_RING metric through ebpf).
Here, tx, rx, and tap all use edge-triggered, and copying can only occur when both sides are ready, so there are three implementation methods:
- Do not record the state: Determine by the return value of read/write, which may incur additional costs, such as when tap is not readable, triggering the read queue to read from tap when rx’s ready is triggered, which is an ineffective operation; similarly, when rx is empty, tap readable triggers the read queue to write to tap, which is also ineffective.
- Record the state of one side (the side with higher operational cost): Obviously, the cost of reading and writing to the virtio queue is not high, the readability and writability of the tx and rx queues correspond to two pop operations of the Available Ring, which are negligible compared to the syscall cost of TAP. We record the readable state of the TAP device, which can solve some of the problems in the first method (recording the TAP state is more important for cases where VIRTIO_F_EVENT_IDX is not negotiated):
- Pop and unpop of tx queue when not readable, as well as some structural transformation overhead.
- Record the state of both sides (tx and rx as well as TAP’s read/write, a total of 4 states): This implementation is the most efficient. It can solve the issues in method 2:
- Determination when tx avail_ring has no data.
- Determination when rx avail_ring has no data.
After analyzing the three implementation methods, considering that the determination of no data on avail_ring is actually quite cheap (the cost involved is memory barriers and numerical comparison overhead), we implement according to method 2.
Event triggering:
- RX Ready: Determine if TAP is readable and copy data from TAP to RX in a loop.
- TX Ready: Copy data from TX to TAP in a loop.
- TAP Read Ready: Copy data from TAP to RX in a loop.
Here, the sending side loop copying is implemented as process_tx, and the receiving side is implemented as process_rx. Later, these three events need to be mapped to their respective logic (for example, events triggered by EventFd need to read the EventFd first, and events triggered by TAP readable need to update the readable state) and these two processing functions. This part of the code will be supplemented after the EventLoop implementation, and here only the two common process functions are implemented.
In actual production environments like firecracker and cloud-hypervisor, rate limiters are also used. After integrating rate limiters, both implementations are relatively complex and have their own issues. Firecracker has a problem with copying data when reading, as it first reads into its own buffer before copying to the desc chain; cloud-hypervisor has frequent epoll_ctl syscalls due to using level-triggered, and also has a lot of ineffective code for handling TAP TX, because TUN/TAP device’s write will never return WOULD_BLOCK (when the kernel ring buffer is full, it will silently drop).
I will try to submit some PRs to address these issues (PR List at the end of this artical).
1 | impl Net { |
TAP Device Impl
TAP devices are used to provide layer 2 networking. Creating a TAP network interface in Linux is straightforward; simply open /dev/net/tun and configure it appropriately using ioctl.
Unlike conventional usage, since we directly relay packets with virtio net headers, it is necessary to remove and add the relevant packet headers when entering and exiting the TAP device. This process can be handled in user space or directly by the kernel: add the IFF_VNET_HDR flag when configuring and set the header length via ioctl.
However, it is important to note that according to the virtio-net protocol specification, corresponding data must be filled in during the forwarding process. For example, the device must set the num_buffers field in the virtio_net_hdr (however, after reviewing the corresponding code in QEMU and Firecracker, I found that they do not populate this field when VIRTIO_NET_F_MRG_RXBUF is not enabled, whereas the specification requires it to be set to 1; so I also looked at the Kernel’s driver implementation, which does not attempt to read this field when VIRTIO_NET_F_MRG_RXBUF is not negotiated. Although not populating it does not comply with the standard, it works for the current virtio-net driver implementation).
1 | pub struct Tap { |
Segment Offload
TAP devices can also be made more efficient:
By adding the IFF_MULTI_QUEUE feature to support multiple queues, and utilizing different threads to handle different queues, this can maximize CPU multi-core utilization and enhance maximum throughput. Whether to support this feature can be decided based on the target scenario, for example, for instances that expect high-density deployment with low per-machine IO requirements, it is not necessary to support this feature. There are no plans to support this feature in this series of articles.
By passing advanced features to the TAP device, such as TSO, USO, UFO. In this case, these bits need to be enabled in the device-supported features, and the corresponding features of the TAP device need to be activated after successfully negotiating the corresponding bits. This blog by Cloudflare provides some reference data on the performance of TSO/USO.
To ensure compatibility, referencing the behavior of QEMU, we need to detect the availability of these features under the current kernel when creating the TAP, and thus construct the device feature.
We need to detect the TAP features and their corresponding virtio features:
- TUN_F_CSUM - VIRTIO_NET_F_GUEST_CSUM
- TUN_F_TSO4 - VIRTIO_NET_F_GUEST_TSO4
- TUN_F_TSO6 - VIRTIO_NET_F_GUEST_TSO6
- TUN_F_TSO_ECN - VIRTIO_NET_F_GUEST_ECN
- TUN_F_UFO - VIRTIO_NET_F_GUEST_UFO
- TUN_F_USO4 - VIRTIO_NET_F_GUEST_USO4
- TUN_F_USO6 - VIRTIO_NET_F_GUEST_USO6
Note: Definitions can be found in version 1.3 and later of the virtio documentation, or in the kernel header.
In the VIRTIO documentation, there are two types of features: one type such as VIRTIO_NET_F_CSUM, and another such as VIRTIO_NET_F_GUEST_CSUM.
The former, without “GUEST” indicates the features for host data reception. For example, VIRTIO_NET_F_CSUM indicates that the host accepts data with partial checksums. If the host declares support for this feature, it needs to perform verification when necessary; if this feature is not negotiated, the guest must ensure that the data it provides has the correct checksum. Therefore, we can enable the TUN_F_CSUM flag for the corresponding TAP device, which indicates that the TAP user can accept unchecksummed packets (corresponding to the comment in iftun.h: You can hand me unchecksummed packets.).
The latter, with “GUEST,” indicates the features for guest data reception. For example, VIRTIO_NET_F_GUEST_CSUM indicates that the guest/driver can accept data with partial checksums, and it will perform checksum verification internally when necessary.
To implement support for offloading segmentation, two things need to be done:
- Guest → TAP direction: The guest needs to send longer segments (meaning that checksum calculations are also offloaded to the host), requiring negotiation of
VIRTIO_NET_F_CSUMandVIRTIO_NET_F_HOST_{TSO4,TSO6,ECN,UFO,USO}(Device can receive); the TAP needs to support sending these types of packets, requiring the enabling ofTUN_F_CSUMand other flags. - TAP → Guest direction: The guest needs to receive longer segments (meaning that checksum calculations on received packets are performed by the guest driver), requiring negotiation of
VIRTIO_NET_F_GUEST_CSUMandVIRTIO_NET_F_GUEST_{TSO4,TSO6,ECN,UFO,USO4,USO6}(Driver can receive); the TAP needs to support reading these types of packets, requiring the enabling of TUN_F_TSO4 and other flags.
Final process (using TSO4 as an example):
- Probe the flags supported by TAP (
TUN_F_TSO4); - Convert the flag to virtio features (
VIRTIO_NET_F_GUEST_TSO4 | VIRTIO_NET_F_HOST_TSO4). This is because TAP supports TSO4, so we can send and receive TSO4 data; - Convert the negotiated feature back to TAP flags (
VIRTIO_NET_F_GUEST_TSO4→TUN_F_TSO4) and set it. This is because enablingTUN_F_TSO4means that we might receive data in this format, and since we pass it directly to the guest, the guest must support it, soVIRTIO_NET_F_GUEST_TSO4must be negotiated to set this flag on TAP;
1 |
|
Peripheral Component Implementation
Bus
Since we may need to mount multiple devices, a component is required to:
- Register devices to address segments.
- Distribute read and write requests based on address segments.
Considering the current existence of PIO and MMIO address spaces and corresponding devices, we can define such a Bus:
1 | pub struct Bus<A, D> { |
The reason for using Arc<Mutex<D>> is that the device needs to be shared by the Bus and event callbacks; the use of Vec within the Bus is because it allows for quick lookup of the device corresponding to an address using binary search.
Implementation of insertion and lookup:
1 | impl<A, D> Bus<A, D> { |
When we need to distribute read and write requests, the device does not care about its absolute address, or rather, it cannot understand the meaning of the absolute address. What it cares about is the offset of the address, so we need to calculate and constrain the offset:
1 | pub trait DeviceIO { |
Thus, we can provide aliases for PIOBus and MMIOBus based on the Bus.
1 | pub type PIOBus = Bus<u16, PIODevice>; |
We can implement a more convenient insertion method for these two Buses:
1 | impl PIOBus { |
EventLoop
Previously, our event processing logic was expressed in this form:
1 | // only pseudocode here |
The flaw of this format is that all logic must be mixed together, and it cannot dynamically register or delete, making the code unmaintainable when there are many events.
We have now added new devices and need to handle multiple events, so it is necessary to implement a more user-friendly EventLoop to solve this problem (the Rust asynchronous runtime I wrote about before is also a kind of EventLoop in some sense, which you can refer to in the Rust Runtime Design and Implementation Series).
The core of implementing an EventLoop lies in how to describe a Callback: we will temporarily define it as T. Based on this, we can implement event registration and define the infrastructure. For implementation, we use Slab to store T, and use the slab id as user_data.
1 | use slab::Slab; |
The EventLoop also needs to provide a function to wait for and process events, which involves event handling logic. At this point, constraints on T are necessary.
Since we can obtain &mut T, the most intuitive constraint we can apply is:
1 | pub trait EventHandlerMut { |
When we try to implement any combination of Arc/Rc and Mutex/RefCell, a problem arises:
With Arc, we can only get a read-only reference to the inner layer, which prevents us from calling its handle_event_mut method!
There are two ways to solve this problem. One is to manually expand the combination and implement the trait for Arc<Mutex<T>> and Arc<RefCell<T>>, forwarding it to T’s implementation. Another way is to introduce a read-only version of the trait:
1 | pub trait EventHandler { |
For Arc<T>, when T implements EventHandler, Arc<T> can then implement EventHandlerMut based on this; for Mutex<T>, when T implements EventHandlerMut, Mutex<T> can implement EventHandler. The effect of this is that if T: EventHandlerMut then Arc<Mutex<T>>: EventHandlerMut, achieving our goal.
We can write its tick method:
1 | impl<T: EventHandlerMut> EventLoop<T> { |
Additionally, regarding the previously mentioned need for dynamic registration after device activation, there are some challenges in supporting this:
- Device activation is executed within the event loop’s handler, where the handler holds
&mut callbacks. - At the same time, this handler expects to register new event sets and callbacks to the EventLoop, which requires writing to callbacks.
At this point, we can introduce a pre-registration to solve this problem (alternatively, we could make the handler a shared ownership structure, cloning it each time to process and thereby releasing the reference to callbacks, but this would introduce some performance overhead):
- pre_register: This operation only adds the callback to callbacks, obtaining a slab id, and requires holding
&mut EventLoop. - associate: Associates the slab id with epoll (i.e., performs epoll_ctl EPOLL_ADD).
The first stage is done at startup, while the second stage can be executed at any time.
1 | pub struct EventLoop<T = Arc<dyn EventHandler>> { |
An EventLoop corresponds to one thread, which can handle all IO, thus achieving lower resource usage and higher deployment density. However, the peak IO performance is not very high because only one or a few threads perform IO operations. Alternatively, each device could have its own thread running an EventLoop (even enabling the device’s MultiQueue feature and starting independent threads for each Queue), which would allow for higher peak performance but at a greater resource cost.
In my code, I used the first approach, simulating all IO on the main thread.
Assembly
We have now implemented all the necessary components, and it’s time to assemble them in the main function.
Here’s a summary of the components we have implemented:
- VM configuration, Kernel, and initrd loading: This part was completed before this section.
- Serial implementation: This was also completed before this section and needs to be mounted on the PIOBus.
- EventLoop: Used for elegantly managing events and executing corresponding Callbacks.
- Bus: Includes MMIOBus and PIOBus, used for dispatching events after VM_EXIT.
- TAP component and Virtio Queue implementation: Used internally by the Net component.
- Net component: Holds the TAP and is responsible for transferring data between the virtio queue and TAP.
- MMIOTransport: Wraps the Net component and mounts it to the MMIOBus, exposing the device operation interface in MMIO form.
In the main function, we can initialize in the following order:
- Initialize logging to provide some observability.
- Create KVM fd, VM fd, and create irq_chip, pit, and initialize memory.
- Create vCPU.
- Load initrd and kernel.
- Initialize registers and page tables and complete mode switching.
- Write boot cmdline and configure Linux boot parameters.
- Create PIOBus and insert Serial device.
- Create MMIOBus and insert MMIO devices.
- Create EventLoop, and register stdin, virtio-net-activate, and exit_evt three fds.
- Start a new thread to simulate vCPU, and notify exit_evt upon exit.
- The main thread starts the EventLoop, and stops the loop and exits after receiving notification from exit_evt.
1 | fn main() { |
Running
After starting the Guest, configure the Host TAP and verify that the Guest can access the Host normally:
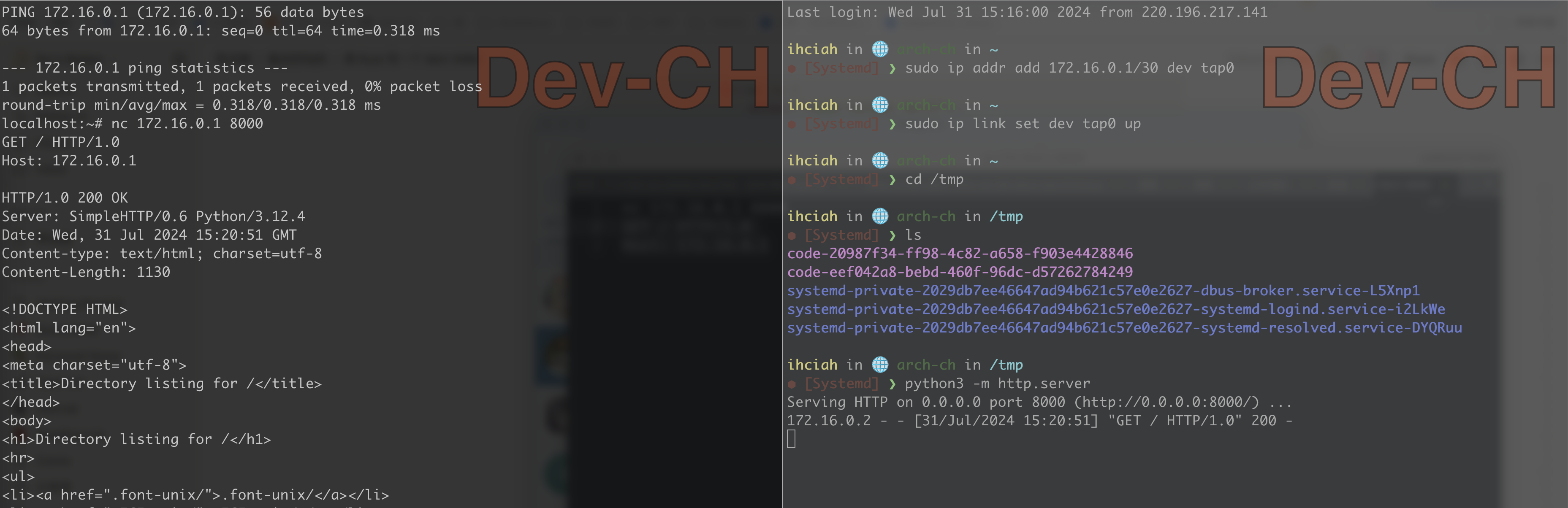
Enable kernel forwarding on the Host and configure NAT rules; after setting up the default route in the Guest, the Guest can connect to the external network:

After a simple configuration of /etc/resolv.conf, you can verify its correct operation by downloading a large file:

The complete code can be found here: https://github.com/ihciah/mini-vmm
Optimizing Open-Source
In this experiment, I referenced some implementations from Firecracker, Cloud-Hypervisor, and QEMU. I adopted their excellent designs in some aspects and proposed what I believe to be superior new implementations in others. I will select a few points that deserve improvement and submit PRs for them (referring to the first two projects). Here is the PR list:
- Remove redundant Descriptor Chain checks for Firecracker: virtio: skip redundant memory check
- Optimize iovec buffer allocation for Net devices in Cloud-Hypervisor: virtio-devices: net: reduce vec allocations for iovec conversion
- General iovec buffer allocation optimization for Firecracker (not submitted due to a conflicting implementation merged later): improve: use persistent buffer as iovec container
- Major refactor of virtio-net for Firecracker: refactor(virtio-net): avoid copy on rx
- Changed from initially reading into a buffer and then copying to the desc chain to directly reading into the desc chain, which is expected to improve performance.
- Added Readiness management to avoid frequent ready checks on the RX Queue when there is no data in the TAP, and to enhance code readability.
- Remove TAP RX Readiness management and switch to Edge Trigger to avoid repetitive epoll_ctl at runtime for Cloud-Hypervisor: working
- Correct TAP offload flag error for Firecracker: fix(tap): use correct virtio feature for CSUM offload
- Correct Queue operation errors for Cloud-Hypervisor: fix(virtq): only enable_notification when about to stop consumption
- The correct approach is to enable_notification after consuming to empty, then check again. The current implementation enables notification every time a desc chain is popped.
- More TODO(this list will be updated)