This article also has a Chinese version.
This article will introduce the design and implementation of a Rust FFI (Foreign Function Interface) framework that I created for calling Golang code from Rust. It will cover the design from the perspective of a designer and implementer, considering various options and explaining the choices made and the reasons behind them. It will also cover some implementation details.
The project is open-sourced on GitHub: https://github.com/ihciah/rust2go. It is a personal hobby project from the beginning, but it is also used in my current company. I will share this topic at this year’s Rust Conf China(2024) and welcome to attend.
Compared to Golang, Rust programs are not garbage-collected and have stronger compile-time checks. Also thanks to LLVM, Rust gets the best possible compiler optimizations, which results in better performance and safety.
At ByteDance, to drive cost optimization, I developed from scratch multiple business-critical Rust SDKs, including service discovery, metrics, log, and dynamic configuration. I initiated and participated in the development of a Rust RPC framework, as well as provided compilation and runtime images, internal crates sources, and a public mirror (rsproxy.cn). Built on top of these infrastructural projects, several core services were migrated to Rust, achieving significant performance gains: a reduction of over 30% in CPU usage and a notable decrease in the P99 latency for some latency-sensitive services. However, many of these services are such that they do not require active maintenance—like proxy and caching services—and hence were easier to migrate. Services with more complex and actively iterative business logic proved more challenging to shift to Rust.
In theory, we could rewrite all Golang programs in Rust to achieve better performance, but in practice, this is met with considerable difficulties: First, rewriting all Golang dependencies may not be feasible; second, completing the rewrite all at once is difficult. If we could provide an efficient way of calling Golang from Rust, it would allow businesses to gradually make the switch to Rust, thereby addressing both issues.
This article covers a lot of ground. The overall narrative flow is as follows: first, I’ll discuss the overall solution selection and provide a minimal PoC; then, starting from this minimal PoC, I’ll expand and refine the solution to support the necessary features; finally, I’ll discuss some implementation details of interest from a framework implementation perspective.
I shared this topic at the 2024 RustChinaConf. If you are interested, feel free to check out the video replay or the PPT(video link, PPT link).
Please note these sharings are in Chinese. But if you have any question, feel free to reach me in any way(you can find my email and telegram in about page).
Note, this article is not a user-oriented usage document.
Solution Selection and a Simple PoC
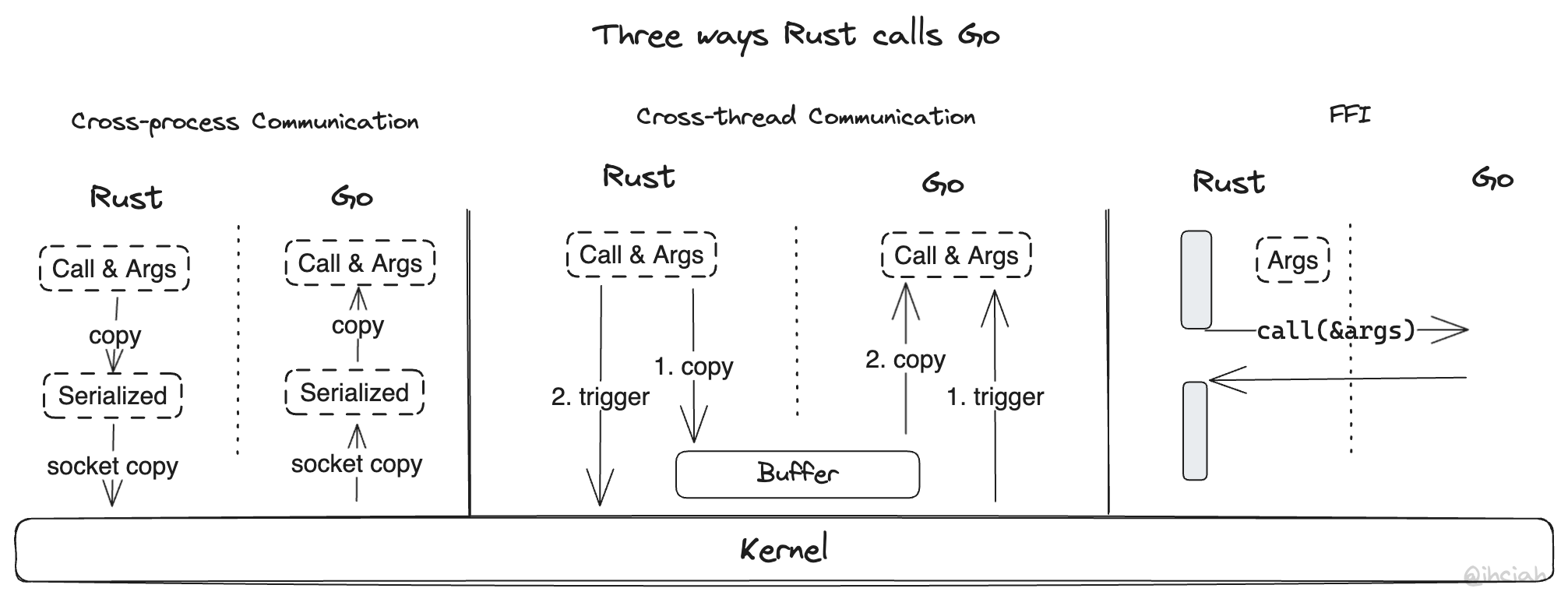
Rust can call Golang in several ways:
- By leveraging inter-process communication (IPC), such as TCP/UDS, and exchanging data via serialization and RPC. This approach is simple to implement and avoids potential memory safety issues. However, the downside is that it’s too slow: it relies on sockets to transfer data, and data must undergo serialization and deserialization. It requires four memory copies and two memory allocations: serialization (one copy, one allocation), socket send (one copy from the application to the kernel), socket receive (one copy from the kernel to the application), and deserialization (one copy, one allocation; here I’m considering multiple fields as a single operation).
- Based on inter-thread communication. If we efficiently utilize the fact that multiple languages share the same process space, we can eliminate some unnecessary copying and context-switching overhead. Data that needs to be transferred can be placed directly in memory, and after pre-agreed data representation is established, the address of the data can simply be communicated to the other side. However, we still require some notification means provided by the kernel, such as eventfd or UDS, which still incur considerable overhead.
- Based on FFI (Foreign Function Interface). With FFI, we can initiate cross-language function executions directly in the current thread. However, different languages have different ABIs (Rust doesn’t even have a stable ABI), so we must use a universally agreed ABI to make regular calls—this agreement is the C ABI. In Golang, we can use CGO to expose C interface functions, and in Rust, we can declare these functions with extern “C”. This allows for direct calls. This method has the best performance, but it requires aligning function calls and memory representation, as well as extra work to support asynchronous tasks.
Simple FFI Example
Any complex task can start with a simple PoC. In Golang, we can expose a function with a C interface using the following code:
1 | package main |
Then, declare and use it in Rust:
1 | extern "C" { |
Finally, generate the Golang static library on the Rust side and assist rustc with linking using build.rs:
1 | use std::{path::PathBuf, env, process::Command}; |
In this PoC, executing go build -buildmode=c-archive generates a Go static library libgo.a and libgo.h in the $OUT_DIR. Afterwards, using cargo:rustc-link-search=native= adds $OUT_DIR to the search path (so the path doesn’t need to be specified separately when using extern "C"), and finally cargo:rustc-link-lib=static=go is used to link libgo.a.
Dive a little deep
So far, we have been able to call simple functions in Golang from Rust (without parameters or return values), but this is far from sufficient for practical needs. To meet actual requirements, we need to support passing more complex data, which involves considering implementation solutions for these capabilities.
Parameter Passing
The previous PoC had no parameters or return values, but in the real world, this kind of scenario is rare.
To pass parameters, we need to consider their representation. A well-known fact is that similar structures in different languages are hard to directly understand by each other. We might have to incur some overhead to align these representations into a “standard format.”
Parameter Representation
We can choose from two schemes for parameter representation: serialization and reference representation.
Serialization is typically used for communication across machines; it encodes data into contiguous memory and uses a fixed byte order (endian). Common text serialization protocols include JSON, XML, and binary serialization protocols like Thrift, Protocol Buffers, Cap’n Proto, etc.
However, for FFI, the parties passing parameters are within the same process:
- Since both sides are in the same address space, data doesn’t need to be sent sequentially, so there is no need for a contiguous data representation.
- As long as the life cycle is correctly managed, there is no need for copying.
- Since the code runs on the same machine, the architecture is the same, so there is no need for endian conversion.

Although the serialization scheme is simpler to implement with readily available components, for performance reasons I’ve decided to use reference representation for passing parameters and return values. Reference representation means passing data that includes pointers to non-contiguous memory. For example, when passing a String, we actually pass the pointer and its length; for a u16, we pass the value of u16 directly (using the endian of the target machine).
When using reference representation, we need to access the memory of the other side, so we need to pay additional attention to its memory representation.
Memory Representation
For memory representation, we can only use structures with a C memory layout, otherwise, the two sides will not be able to understand each other.
For example, when passing a Vec<u8>, even though it internally consists of a pointer and length, we can’t pass the structure directly because the Rust compiler might insert padding or reorder fields. So for this requirement, we would place the pointer and length in a struct and pass it, adding #[repr(C)] to control the structure’s memory layout.
The case with String is similar: I represent String as a StringRef, defined as follows:
1 |
|
For user-defined structures, similar reference structures can also be defined, such as:
1 |
|
In practice, such reference structures can be generated using build.rs or derive macros (this will be detailed in the implementation section of this article).
Return Value Passing
For parameters, we need to obtain their reference type from ownership types; for return values, the process is reversed: we need to dereference. On the Golang side, data containing pointers is returned, which then needs to be converted back into ownership type data on the Rust side (taking into account whether copying is necessary).
When dealing with pointer dereferencing and copying, two new issues arise:
- How to ensure the legitimacy of the pointer reference?
- Should we copy the data, and how should memory be allocated?
Let’s discuss a few approaches to see if they can meet the two issues mentioned above.
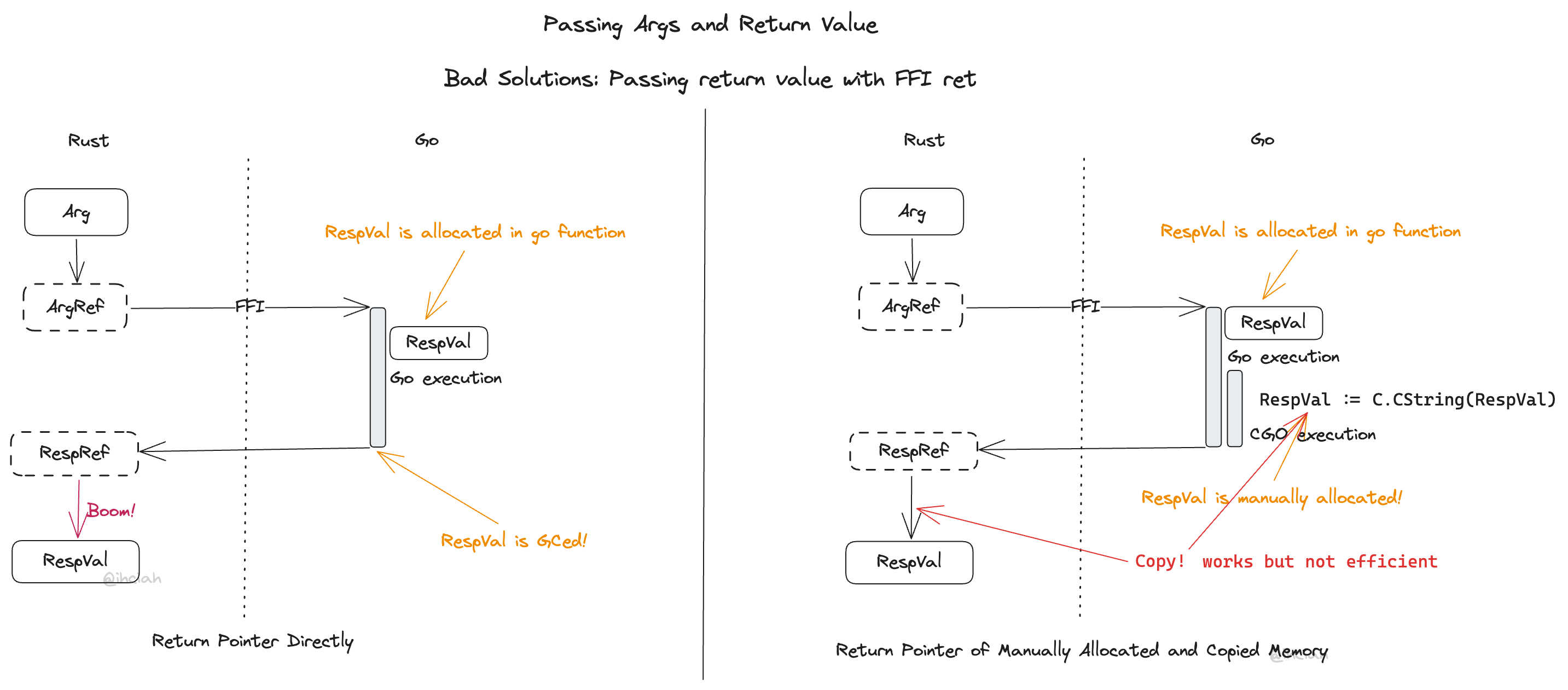
Approach 1: FFI Returns Pointers Directly
In Golang, once a function is executed, all unreferenced data is released upon garbage collection, making pointers returned to Rust dangling, which can lead to unexpected consequences. Therefore, this method fails to guarantee the validity of pointer references, and it doesn’t even address the second issue.
Approach 2: FFI Has No Return Value; Rust Allocates Memory in Advance
With this approach, memory for the return value is pre-allocated on the Rust side. When calling the function, a pointer to this memory is passed, and before the Go function completes, it actively copies the return value to that memory.
This method seems to solve the first issue because Golang copies data to the Rust side.
However, there is still a problem with memory ownership: when copying a String, it must be a deep copy, and the memory allocated in Golang still belongs to Golang; it cannot be transferred to Rust.
One mitigation is to manually allocate memory and copy data in CGO. This means the Rust side must pre-allocate a slot where Golang can write the pointer-containing return value representation, ensuring pointer validity. An additional interface allowing Rust to release corresponding memory after use must be exposed. But this mitigation increases complexity, and the overhead of additional FFI calls for memory release (proportional to the number of objects) is considerable. Rust might need to use a special Allocator for Strings and Vecs (affecting ease of use) or incur additional copying costs (affecting performance). This solution may even perform worse than serialization.
Approach 3: Passing Return Value Via FFI
What if we pass the return value with an additional FFI call? In this case, we can hold Golang memory from being released while switching to the Rust environment, ensuring Golang pointer validity while allowing for proper memory allocation.
Passing Return Value Via FFI
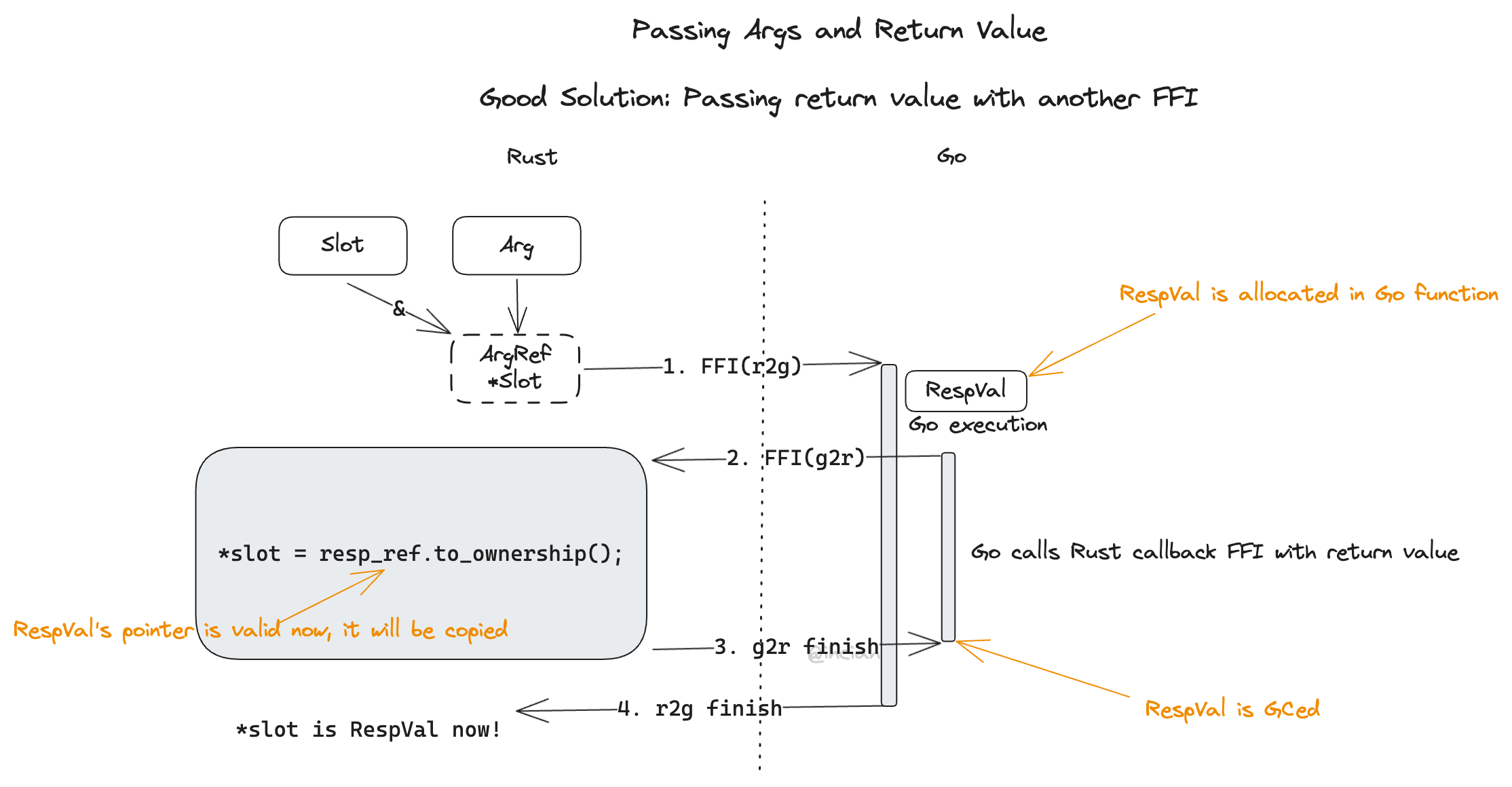
We can call Rust again in the same thread where Rust is calling Golang. As we cannot control the lifetime of the return value Rust side receives (the upper layers might even store it in a global structure), the copy upon being called by FFI on the Rust side is inevitable; Rust performs the copy after being called, allocating its own memory and normally releasing it upon Drop.
Now we just need to consider how to execute the callback FFI.
The current idea seems to require Golang to directly call Rust, so Rust must expose itself as a library and be linked by Golang. This complicates the compilation and is quite perplexing: why do I need to expose Rust as a library if I’m only calling from Rust to Go?
However, since it is a callback function, we can pass the pointer over, and theoretically, the call should be possible – function calls simply involve stacking the return values and parameters or setting them in registers before calling the function address. The effect of exposing as a library is merely writing the corresponding function name and address into the export table, which should produce the same effect as passing a pointer when initiating the call.
Golang Jumping to Function Pointers
Calling Rust from Golang still faces ABI inconsistency issues.
One solution is to use an assembly snippet to forcibly align ABIs (when attempting this approach, I found a very interesting related implementation: Hooking Go from Rust). However, given that Rust’s ABI is unstable and we will need to address goroutine stack expansion when supporting asynchronous operations later, I did not choose this option.
Actually, the solution I used is simpler: directly using CGO – Rust side exposes the callback with a C ABI, and in CGO, the function is defined, cast to a C function pointer, and called.
Why use CGO? Functions executed in goroutines perform a stack space check upon entry. If it’s insufficient for its needs, it will expand the stack at runtime; however, when performing FFI, this checking and expanding behavior cannot be inserted. When issuing an FFI call using CGO, Golang will switch to the G0 stack to avoid potential stack space issues during the FFI call.
1 | package main |
Memory Safety
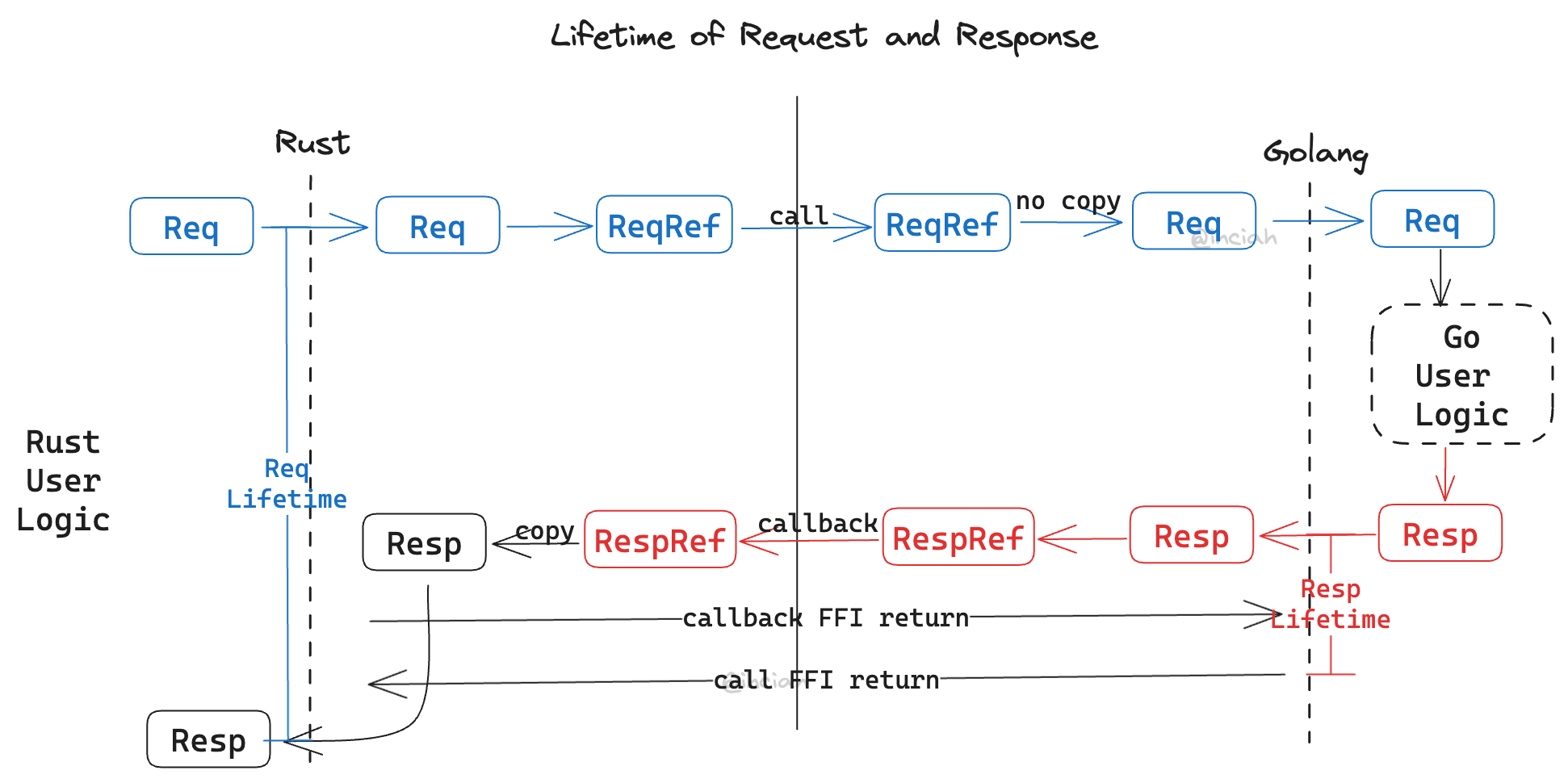
We are currently considering two types of structures: ownership types and reference types.
- When Rust initiates an FFI call, it holds the ownership types of the parameters and passes the reference types to Golang. During this time, the Rust thread is occupied and cannot release the ownership types, making it safe.
- The Golang function can safely use the passed parameters’ pointers while it’s executing in a blocking manner.
- After the Golang function completes, it sends a reference of the return values to Rust via another active FFI. This ensures that Golang’s ownership types aren’t GC’ed.
- The Rust side receives a pointer to the return value from Golang and needs to copy the data to Rust memory immediately.
- Once the callback FFI concludes, Rust has completed copying the return values, allowing Golang to release them.
- When the Rust call completes, Golang must stop holding onto the parameters with references (parameters that haven’t been manually copied should only be used with functions that prevent lifetime leaks).
Asynchronous Support
For Rust’s asynchronous system, refer to my previous article.
It’s difficult to avoid asynchronous programming in network programming, and the invoked Golang code is often the same. Using the previously discussed support, we would find that the Rust-side threads are blocked by the Golang call during network IO by Golang. This would result in a significant drop in worker thread utilization, translating to a spike in request latency and a drop in load capacity.
The simplest way to solve this problem is to use spawn_blocking, which is typically provided by the Rust runtime. spawn_blocking is designed to offload heavier or blocking logic to a separate thread pool for execution and wait asynchronously, allowing worker threads to handle other tasks during the waiting period.
However, this approach is only suitable for less frequent, heavy synchronous tasks. If synchronous tasks take a longer time and are more numerous, many threads will incur significant context-switching overhead. When synchronous tasks are on the hot path, the asynchronous runtime essentially becomes comparable to a Java-style thread pool.
Comparison of Rust and Go Coroutines
Rust uses stackless coroutines, where tasks must actively yield when they are pending and are rescheduled by the event source that notifies the runtime.
Go uses stackful coroutines, hiding netpoll details and allowing users to initiate blocking syscalls with support for preemption.
These are two completely different models.
More Efficient Asynchronous Support
Rust tasks run in the Rust-side runtime, and Golang tasks execute on the Golang side; both at the core are asynchronous non-blocking IO. There’s no need to meddle too much with task switching, nor is it necessary to entertain the notion of throwing Golang tasks into the Rust runtime.
In fact, all we need is the ability to execute Golang functions non-blockingly and receive a notification when they’re done. Do we need to hack the Go runtime? Maybe it works. But there’s a simpler approach: go task(). The solution lies in the riddle itself – the most common go keyword is the secret to executing Golang functions non-blockingly.
We just need to wrap the user-provided function like so:
1 | func wrapper() { |
Then, just wake the corresponding waker within the callback implementation.
However, it’s important to note that Rust allows tasks to be woken spuriously, and the Golang execution of the callback is done on a Go thread, so we must ensure that the callback execution and the task wake-up on the Rust side (to read the return value) are concurrency safe.
To wake up the task in the callback, the Rust side must provide not only the callback pointer, parameter list, return value slot pointer but also a waker when initiating the FFI. Golang then initiates an FFI call to the function pointed to by the callback pointer, passing the return value slot pointer and the waker. For example:
1 | /* |
On the Rust side, all that’s needed is to provide a layer of Future which takes a waker and initiates the FFI. Within the callback function, a Waker is constructed from a WakerRef structure and then executed with wake:
1 |
|
Complex Type Support
Previously, I categorized structures into ownership structures and reference structures.
- Ownership structures can be directly converted into reference structures, for example,
String -> StringRef {ptr, len},Vec<u8> -> ListRef {ptr, len} - Reference structures can copy into ownership structures, e.g.,
StringRef {ptr, len}->String
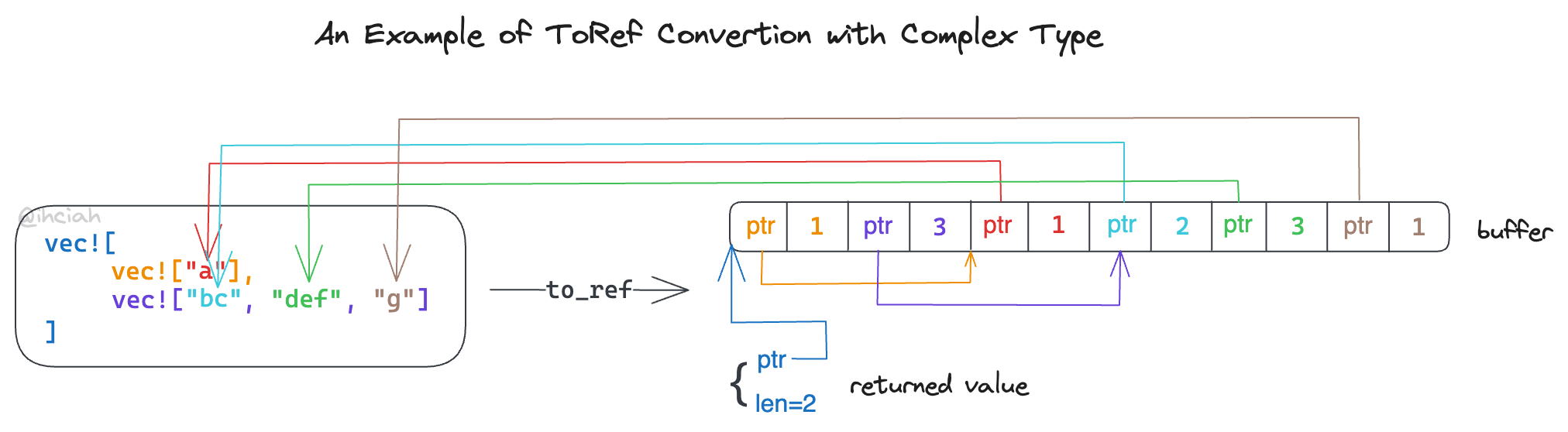
However, this is not always the case. For instance, a Vec<String> cannot be converted similarly. Taking a pointer to the outer Vec gives a pointer to the String, which Golang cannot understand; it still needs to convert each String into a StringRef {ptr, len}. To construct a pointer to multiple StringRefs, space must be allocated to store these intermediate structures.
My initial design was to define an additional intermediary type (tentatively called a Shadow type) to store intermediary results. The reference types actually depended on both the intermediary type and the ownership type, used as Ownership -> Shadow -> Ref.
However, this approach resulted in overly complex struct definitions (e.g., Vec<Vec<Vec<u8>>> required multiple intermediary structure fields) and the intermediary types introduced multiple allocations, thus I ultimately did not adopt it.
Returning to the problem itself, since we need to store intermediary structures, is it possible to use a single contiguous block of memory? Indeed, it is, and this approach can reduce the memory allocation overhead of the entire structure conversion to just one instance. The trait for conversion might be defined like this (the actual implementation differs, applying more type calculations and constant optimizations):
1 | pub trait ToRef { |
During recursive conversion, if a child structure needs to write to intermediary storage, it will write on its own and return a possibly pointer-containing structure that references the intermediary storage. The final top-level structure returned is the data to be sent via FFI.
Framework Components and Implementation
By now, we have essentially discussed clear solutions for all the key issues and could manually implement a Rust wrapper for calling Golang based on our needs.
However, my goal is to provide a universal and user-friendly framework that allows users to use it out of the box, avoiding the many complexities previously discussed. Therefore, it is necessary to provide generic foundational components and a code generator.
Describing Calling Conventions
Users need to provide FFI function definitions and related structure definitions. Typically an Interface Definition Language (IDL) would be used to describe this calling convention, such as uniffi implementing a UDL to define these conventions.
But using an IDL can also bring a learning curve to users, and requires developing a corresponding parser and ecosystem (such as IDE plugins).
Here, considering that this project clearly focuses on Rust calling Go, and since Rust’s traits essentially align with calling interfaces, I decided to use Rust syntax (but restricted to use only part of the syntax) as the IDL. This approach doesn’t require additional learning for users, can directly utilize libraries like syn and quote that process Rust code, and this IDL can also double as ordinary code used by Rust projects.
Users can define structs and traits, with traits supporting synchronous and asynchronous functions (asynchronous functions described using the stabilized async-fn-in-traits feature).
For example, an acceptable interface convention might look like this:
1 | pub struct DemoUser { |
Code Generation Approach
Based on our problem analysis, we can summarize the types of code needed:
Golang side ownership structure definitions, reference structure definitions, and exported ffi functions
Golang code needs to be all manually generatable because this code might be copied to an independent Go repository. This way, the Go project can be independently developed and compiled without depending on the Rust environment. If version consistency needs to be ensured, the same generator can be called in the Rust project’s build.rs to regenerate and overwrite Go source files.
In this implementation, C structure definitions (reference structure definitions) are generated through cbindgen. First, parse the Rust files, complete the Ref structure generation, and then use cbindgen to generate the corresponding C code, which is then inserted before
import "C"in the Golang code. The rest of the code needs to be manually formatted by the Rust side.Rust ownership structure definitions, reference structure definitions, and exported callback ffi functions
The ownership structure definitions have already been provided by the user and don’t need to be redefined. The reference structure definitions and callback ffi need to be generated through code, which can be achieved by parsing and constructing a TokenStream and writing it to a file.
In this implementation, the reference structures and callback ffi are generated by derive macros. This work actually shares the same logic as the code generation of Ref structures mentioned earlier.
Rust Trait Definitions, Conversion Trait Definitions
Trait definitions have already been provided by the user and don’t need to be redefined. Conversion traits as a generic definition are not influenced by the user and can be defined in the public library.
Rust Trait Implementations, Conversion Trait Implementations
In this implementation, the implementation of the Rust FFI Trait and conversions are done using macros.
Using macros for code generation is preferable to using build.rs. This approach has lower coupling, higher compile efficiency, and is more friendly to IDEs. An additional note is that because linking with Golang results in the import of a C structure definition, there are actually two sets of reference structure definitions generated. Here, a direct transmute is used to solve the issue of duplicate definitions.
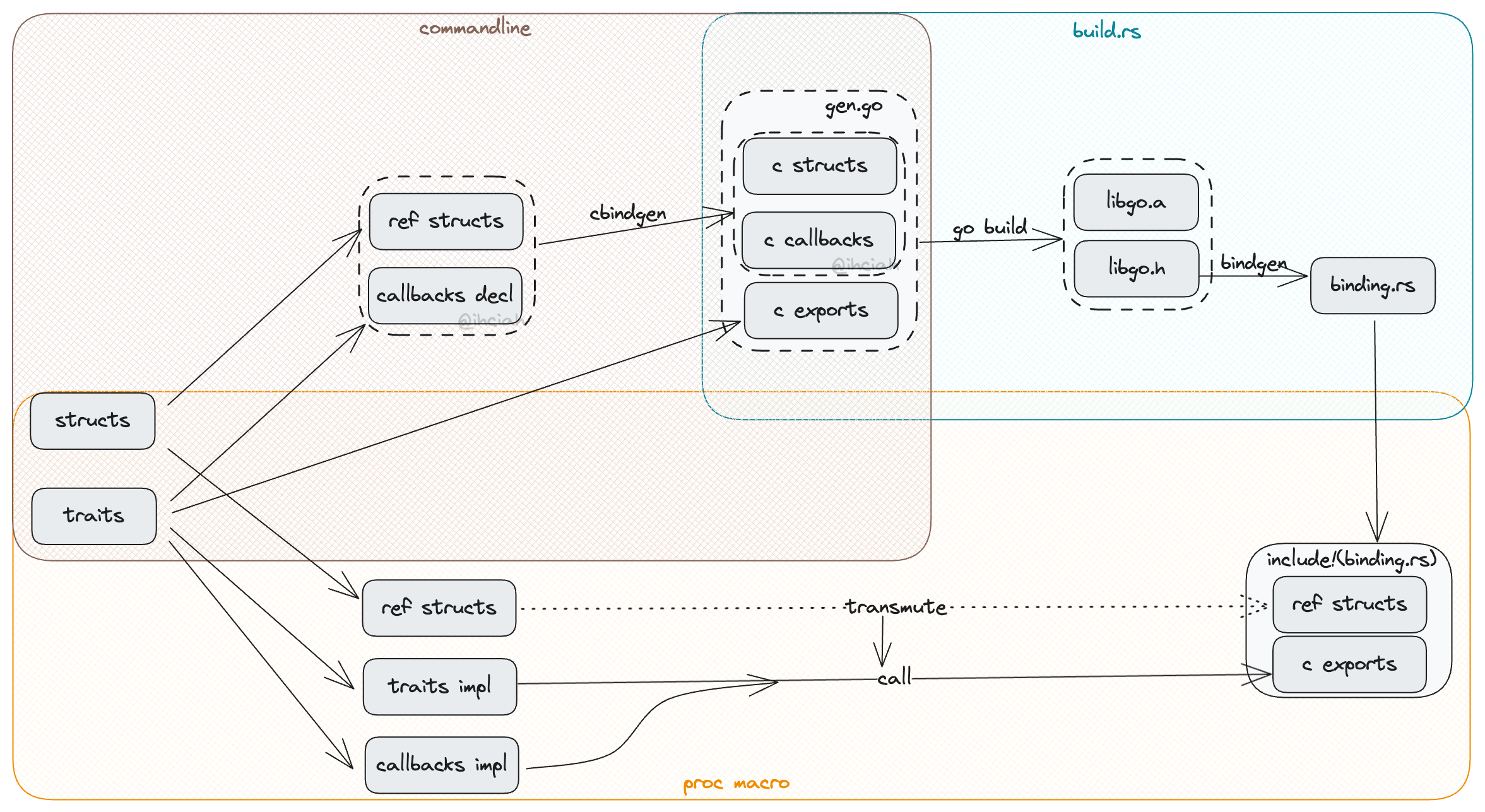
Definition and Implementation of Conversion Traits
Conversion traits are used for converting between ownership types and reference types.
ToRef
Based on the previous analysis, some ownership structures require intermediate storage when converting to reference structures.
Since the data written inside the intermediate structure are pointers, and these pointers will reference the buffer itself, it’s necessary to allocate sufficient space in one go without being able to expand partway. Thus, we clearly need two interfaces: one to calculate space occupancy and another to perform recursive conversion and write data.
We can consider the following typical examples:
u8: This type of data never requires intermediate storage.Vec<u8>: This type of data does not require intermediate storage when it is the outermost structure, but it does when there is another structure surrounding it.Vec<Vec<u8>>: This type of data always requires intermediate storage.
Based on this discussion, I categorize data into three types:
- Primitive: Basic types, such as u8, u16, char, etc., can be freely copied; for space calculations, simply return the current structure’s size; to convert to a reference, return itself.
- SimpleWrapper: A single-layer reference to Primitive types, such as
Vec<u8>,String,Vec<u16>,Map<u8, u16>; for space calculation, return the memory size occupied by the pointer and length; to convert to a reference, return the pointer and length. - Complex: Types that contain references to SimpleWrapper types, such as
Vec<Vec<u8>>,Vec<String>,Vec<Map<u8, u16>>; for space calculation, the calculation needs to include the size of the structure itself and recurse; to convert to a reference, recursive conversion is needed, and the results of the current layer’s conversion are returned.
These three types will determine whether we need to perform recursive calculation of space occupancy and conversion. By utilizing this, we can avoid recursion for the innermost structures. Thus, we can define the following trait for ownership to reference type conversion:
1 | pub trait ToRef { |
At this point, we can implement the conversion for Vec<T> where T implements the conversion trait:
1 | impl<T: ToRef> ToRef for Vec<T> { |
When converting Complex types, it is necessary to first reserve the buffer space required for their children and then sequentially write the results of each completed child conversion into the reserved locations. Below is an example of a conversion:
Of course, the same logic also needs to be implemented on the Golang side. However, due to the lack of robust generic support (for instance, Golang doesn’t support generic semantics like impl<T> Trait for T), this part inevitably requires manually constructing multi-level functions to achieve the desired result.
FromRef
On the Rust side, the trait for constructing ownership structures from reference structures can be intuitively defined as:
1 | pub trait FromRef { |
For complex types, we can have a relatively straightforward implementation, such as:
1 | impl<T: FromRef> FromRef for Vec<T> { |
On the Golang side, similar logic also needs to be implemented. We can define some helper generic functions to simplify code generation:
1 | func newSlice[T any](_param_ref C.ListRef) []T { |
For a complex List like the following, using the aforementioned helper generic functions, a simple conversion implementation can be generated:
1 | type DemoComplicatedRequest struct { |
Memory Safety During Asynchronous Calls
Drop Safety
Unlike synchronous calls that occupy the Rust side thread and can thus ensure that the data being referenced is not deallocated, asynchronous calls immediately return from the Go FFI function, and the callback FFI is executed after the user logic has finished in the background. How do we ensure memory safety in this situation? If users drop the Future prematurely (which should be safe), how can we prevent Golang from accessing incorrect memory addresses at that moment?
This issue is fundamentally the same challenge faced when implementing a Rust Runtime based on io_uring (you can refer to my article Rust Runtime Design and Implementation - Design Part 1). The question is how to guarantee the lifecycle validity of the data corresponding to a pointer after it has been submitted to the other side and until completion notification is received from the other side.
In Monoio, inspired by tokio-uring, I took ownership of the related buffer, transferred ownership of the buffer to the heap before submitting it to the kernel, and leaked it, then stored the pointer in a global structure; upon receiving kernel completion, I reconstructed and released it from the pointer.
In this case, to ensure memory safety, we have to adopt a similar method to avoid the problem of Golang accessing the wrong memory address if the Future is dropped too early. There might be issues with parameters being released too early or the Ret Slot being released (in synchronous implementations, the Ret Slot can be on the stack; in asynchronous implementations, we must place it on the heap).
Ret Slot Lifetime
After the Rust side drops the Future, I would like the Ret Slot not to be released: the release timing of the Ret Slot should be after Golang has finished writing and Rust has completed reading or dropping. For this purpose, I designed an Atomic structure to store the return value (complete implementation).
1 |
|
State is an atomic status that encapsulates CAS operations; SlotInner holds the state and data, encapsulating read and write behaviors; SlotReader and SlotWriter provide read and write capabilities and conditionally release SlotInner upon Drop (when both Reader and Writer have been dropped).
Based on this atomic Slot, we can ensure that:
- After the Future is dropped, Golang can still legally write data into the Slot.
- After the Future is mistakenly woken up, it won’t race with the writing logic initiated by the Golang side.
Parameter Drop Safety
For input parameters taking ownership, we can store them in a similar way as the Ret Slot. Since their lifetime aligns with that of the Slot, to reduce heap allocations, we can directly store the parameters inside the Slot:
1 | struct SlotInner<T, A = ()> { |
For example, the above A might correspond to type (arg1, arg2, arg3).
However, if the parameters include reference types, we still cannot ensure Future drop safety.
I defined a #[drop_safe] attribute: if a function contains this attribute, then its parameters must be ownership types, otherwise, an error will be thrown. To allow users to reclaim argument ownership after performing the call, I additionally defined a #[drop_safe_ret] attribute, which is functionally similar to #[drop_safe], the difference being that it influences the return value, making the return type something like (Ret, (ARG1, ARG2, ARG3)).
For asynchronous functions that do not have these two attributes, in the generated code, I will add an unsafe marker to inform users they must ensure that the Future is not dropped before it returns Ready.
In this section, I’ve discussed how to represent calling conventions from an implementation perspective, what means are used to generate code, how to generate reference structures and implement the conversions between ownership and reference structures, and finally, the design for ensuring memory safety during asynchronous calls.
Ultimately, using this project one can achieve efficient (theoretically the most efficient solution) Rust calls to Golang, with support for asynchronous calls. In the future, the project also plans to support active calls from Go to Rust.
Better Performance
Go FFI and FFIs of other native languages differ in that when other languages call Golang, the Go code does not directly execute on the caller’s thread, but is dispatched to a thread managed by Go’s own runtime. The previous solution depends on CGO to provide the related dispatch implementation.
Using CGO results in switching to the G0 stack when the Golang side calls the Rust side, and Golang also requires cross-thread dispatch when being called. Considering these costs, abandoning CGO and exploring other higher-performance cross-thread communication methods may further enhance performance (CGO’s implementation was underperforming before version 1.21, with significant optimizations in version 1.21).
A simpler solution would be to use common methods such as TCP or UDS for communication, sending and receiving call information. However, considering that Go and Rust run in the same process and share the same memory space, a further approach is to use shared memory and some notification mechanism for communication, potentially reducing the number of cross-thread communications.
Here I implemented a shared memory-based mechanism to replace CGO, with the notification mechanism based on EventFd/Unix Socket.
Memory Ring
Memory Ring is the core part of this functionality. I made it into a standalone library, available for use if you have similar needs (includes Rust and Go implementations, with Rust supporting tokio/monoio): https://github.com/ihciah/rust2go/tree/master/mem-ring.
This Ring includes shared memory reading and writing, status bit reading and writing, and the implementation of cross-thread notification mechanisms to handle situations where the ring is empty or full.
A Ring is designed to be used by both sides at the same time, one side reading only and the other side writing only (bi-directional read and write require two Rings). Its structure includes:
- The pointer and length of the buffer, the length corresponding to the number of
Ts - head and tail index, using u64 for storage, expected to not run out due to monotonic increment
- working and stuck markers
- fds for working and unsticking notifications
While reading data:
- Set the working bit to 1, then begin sustained consumption.
- Each consumption round reads the tail and calculates the remaining length, reads the data then updates the head; also checks the stuck bit, if set to 1, notifies the unstuck_fd.
- When the consumption reaches an empty state, first perform a short wait (e.g.,
yield_now, orruntime.Goschedin golang), then continue reading the tail to determine the length, if not empty, continue with the regular consumption logic. - If it’s still empty after a short wait, set the working marker to 0.
- Since there might be new data right at the moment of resetting the working marker to 0, again read the tail to determine the length, if not empty, set working to 1 and continue the regular logic.
- If it’s still empty, go into a wait, waiting for a working_fd notification.
When writing data:
- Read the length, if the ring is full, set the stuck marker to 1, and add the data to the Pending queue, then complete the write.
- If the ring is not full, write into the ring and update the tail.
- Check if the working bit is set to 1, if yes, then the write is done.
- If the working bit is 0, wake up the other side: set the working to 1 and notify the other side through the working_fd.
Additionally, we need a background task responsible for moving tasks from the Pending queue into the Ring):
- Take tasks from the Pending queue and try writing into the queue, continue with more tasks if successful.
- If the queue is full, return the task and break the loop.
- If the Pending queue is empty, also break the loop.
- After the loop exits, check the working marker, if not working, notify the other side through the working_fd.
- Check if the Pending queue is empty, if not, indicate not all tasks could be moved, continuing stuck marker.
- Check if the queue is not full, if not, jump to step 1.
- If the queue is still full, wait for unstuck_fd notification.
By implementing these logics in both Rust and Golang, we have completed the fundamental construction of the Ring, supporting both empty and full states using EventFd/Unix Socket for notifying peers.
Among them, the working flag design significantly reduces the number of cross-thread notifications. In the benchmark, it can be observed that the batch ratio is about 150:1.
Calling Convention Representation
Using two Rings, we have already built an efficient bi-directional communication mechanism. So, how do we represent calls and return values based on these two Rings?
Let’s consider a call with no return value. Since the call involves passing a pointer, and the corresponding memory release needs a return packet to be determined, a call with no return value actually corresponds to two communications.
Similarly, a call with a return value also needs to consider the lifespan of the return value, so it could be accomplished with four communications; with good design, optimized to three calls.
Here, I designed a general Payload structure:
1 |
|
Parameters are represented by ptr, multiple parameters when stored sequentially in corresponding memory; function name represented by call_id; also has a user_data to uniquely identify requests;
finally, for calls with return values, using next_user_data to combine the notification of parameter release and return value, accomplishing a function call based on three interactions.
Temporary Variable Storage
After sending a pointer to the peer, the object corresponding to the pointer cannot be immediately released. It must wait until the function call is over and the release notification from the other side is received.
At this point, we need a place to store this structure. One way is to use Box to store it on the heap and leak it, filling user_data with the Box pointer.
However, this method requires additional memory allocation, and because storage and release are very frequent, we can consider storing these data in pre-allocated slots.
Here, I chose to use a Slab storage method (maintained by the tokio team crate), which can operate at O(1) complexity, and the memory is tightly arranged for high utilization.
On the Golang side, I implemented a version of Slab with segment locks, which also achieves good performance.
Putting it all together
To be compatible with the original CGO-based implementation, I modified macro here, added a new #[mem] definition, and for functions with this attribute, generated an implementation based on shared memory. Also, modified the r2g process macro, allowing users to specify queue size. For example:
1 |
|
The usage is indistinguishable from the CGO version. Finally correctly responding:
1 | ========== Start oneway demo ========== |
In benchmark scenarios, using Go 1.18, the shared memory mode shows a positive optimization over the CGO-based implementation across various parameters, optimizing up to 20.01%.