This article also has a Chinese version.
This article mainly summarizes common issues and thoughts in proxy framework design; it also touches on some engineering designs within the Rust + Tower ecosystem. Although there’s already plenty of discussion on this topic online, who knows, maybe after reading this article, you’ll come up with a new idea? Found out that since joining the company, I’ve been writing nothing but proxies
Theoretical Part
What Does a proxy Do & What Is Needed for a proxy?
What Does a proxy Do?
As the name implies, a proxy’s main job is traffic forwarding. Beyond this core function, proxies often take on the following responsibilities (not all concepts apply to every proxy):
Service Discovery
In Service Mesh, for example, proxies often handle service discovery, allowing business logic to simply connect to the local proxy.
Before performing service discovery, we need some metadata about the request. This metadata might be directly obtained from the connection itself, such as based on
client ip:portorSO_ORIGINAL_DST, or it might come from the traffic, such as a service name indicated on an HTTP request header (which means the proxy might need to partially parse the traffic).Protocol Transformation
Protocol transformation refers to format transformation at the level of the entire stream, the request headers, or the request body.
The commonly used ShadowSocks, for example, performs protocol transformation at the connection level, where it can convert exposed socks5 protocol to its own custom encrypted protocol and back again. Nginx, usually serving as an entrance gateway, often takes on the responsibility of offloading TLS, which is also a type of protocol transformation.
Authentication Filtering
proxies are not necessarily transparent: while they forward traffic indiscriminately, centralized control can be crucial. proxies can perform authentication, filtering, signing, and other fringe functionalities.
Through this intermediary layer, services behind the proxy can unconditionally trust incoming traffic. This approach is widespread within companies. Common application scenarios include risk control.
Load Balancing
Separating traffic distribution from traffic handling can significantly enhance the information processing capacity of the entire system.
Using certain load balancing algorithms, we can distribute requests to different handlers without impacting the service. At this level, you might even think of your bosses as proxy-like, as they are responsible for breaking down major tasks into smaller ones and ultimately distributing them to specific Workers to execute.
What Is Needed for a proxy?
Acquisition / Updating of Service Metadata
In scenarios where service discovery is required, the proxy needs to function as a service discovery client. The simplest implementation might involve embedding a Consul Client. Besides this, the proxy might need to manage services, with related configurations such as timeouts, retries, and authentications also being part of service metadata.
Note that this metadata can be updated, and our proxy usually needs to dynamically update this information. Nginx is not very flexible in this regard, and although it is high-performing, it has been abandoned by mainstream Service Mesh; Envoy offers xDS which, combined with a control plane, provides the dynamic capabilities needed by Service Mesh and is even replacing Nginx due to dynamic configuration.
Protocol (Header) Decoding / Encoding
Pure layer four proxy scenarios are quite limited. In other scenarios, it is difficult to avoid being aware of the request—if we need to achieve this, we need to understand the protocol, at least to be able to parse the protocol header; in some scenarios, we even need to parse the protocol body.
For instance, in Service Mesh scenarios, we need to perform service discovery for HTTP requests, which clearly cannot be connection-level proxying. We need to parse the protocol header to 1. distinguish request & response boundaries and 2. gather metadata.
If we sacrifice transparency—which I think is quite useless in non-HTTP scenarios in Service Mesh—we can do much more, just like what Dapr does: it abstracts various middleware, reducing the cost for businesses to learn & switch middleware and also decreasing the coupling between business code and middleware. In the microservices environment, it facilitates more rapid middleware version iterations.
Load Balancing Algorithm
Even load balancing must respect principles. Whether it’s Round-Robin, Random, or p2c is usually a choice for the user to make, as different scenarios have different requirements. How to calculate the hash is also strongly related to the business.
Dynamic Logic Insertion Ability
In scenarios such as risk control, where rules might be frequently updated, obviously weaving such logic into proxy code for compilation isn’t ideal. Some components also hope to inject logic into proxies (such as more niche/less universal internal protocols).
Injecting logic is not easy and involves performance and usability trade-offs.
How to describe universal logic?
- Process: The simplest & most compatible & free way to describe universal logic is through processes. Custom logic in the form of processes communicates with proxies via IPC. Despite its freedom, it has clear drawbacks—the IPC cost is huge, and state management cannot be handled by the proxy.
- Code: For instance, we can support users providing a snippet of Python code, and the proxy starts a Python virtual machine to execute this logic. It looks ideal, but this binds us to a language and can only be adapted to scripting languages; languages that need compiling will suffer.
- Is there a universal & easy-to-manage representation? WASM might be one (or the envisioned WASM). WASM is relatively lightweight, and proxies that start virtual machines with built-in JIT can achieve performance that isn’t too bad, which is sufficient for most traffic filtering logic.
Is Proxy Good? Is Proxy Bad?
It’s hard to imagine a production network without Nginx, facing issues like insufficient processing capacity (assuming all Workers are hung on DNS with public IPs) or difficulty in rolling updates (updates would cause partial service interruptions).
However, a network with too many proxy layers can lead to increased latency and wastage of computing resources (whether it’s a centralized proxy or a Sidecar mode proxy). For a centralized model of proxy, there are also isolation problems.
If we understand proxy from a more abstract point of view (and remove some frills), we can divide its capabilities into two parts:
Traffic / Data Isolation
Once traffic gets messy, it indeed requires a central proxy to separate it, which is a given.
Due to the limited number of public IPs, these traffics inevitably get messy; in other scenarios, inherently separate requests become artificially muddled together after passing through a central proxy.Logic Isolation
In Service Mesh or Dapr scenarios, the proxies here mainly serve to isolate logics. proxies aiming for logical isolation can be eliminated by merging codes.
What does that mean? For example, if you copy the governance logic from within the proxy directly into the business code and compile it into a binary, the proxy’s IPC becomes a function call, and the effect is the same. Splitting into two processes is purely to isolate logic.
proxy may be one way to solve code coupling, but I believe there are better ways to tackle this issue: My view is that the future of proxy is
no proxyas few as possible and unified proxy. However, this generation’s cloud-native model might find it hard to achieve.
Engineering Part
Here, we won’t discuss the pros and cons of the proxy model or its necessity; instead, we focus on how to implement an elegant proxy.
Since the author was too clumsy to learn C++, some sections of this chapter are coupled with Rust and assume the reader has a basic understanding of Rust. (Why not use Go? To quote a famous saying: Go is trash A language with GC for proxy, latency-sensitive services would explode.)
Logical Combination Patterns
At the end of the day, a proxy’s process is straightforward:
- Listen + Accept
- Receive Request + proxy Request + Receive Response + Return Response
The complexity within a proxy lies in the intermediary governance logic (after all, you don’t want traffic to flow freely without putting CPU and latency to some use).
The most naive approach is to write everything together, making it hard to maintain (enhancing my irreplaceability). If you want to avoid a mess, there are generally two patterns available:
Filter Pattern aka. Filter Chain
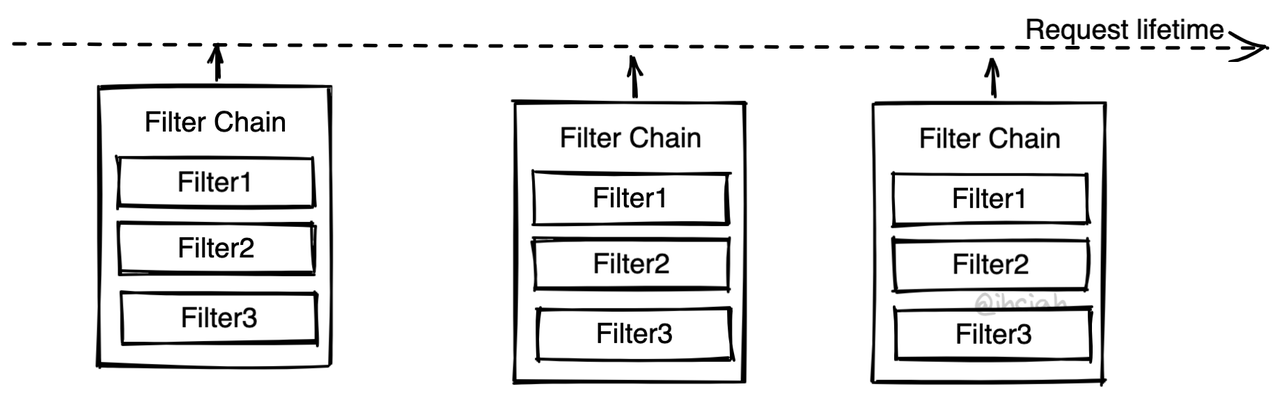
Envoy uses a Filter Chain pattern (here, a Filter is not a function that returns a boolean to judge, but something that manipulates data with side effects). Components with different purposes are inserted into the Chain as Filters, and traffic passes through the Chain to be treated by each Filter.
In addition to Envoy, Mosn and Quilkin also follow a similar pattern.
This pattern is typically implemented by the framework, which takes care of the main link logic and provides insertion points to support multiple Filters. At fixed insertion points, the Filter interface is fixed, which means there are certain restrictions in programming but also simplifies it.
Onion Pattern aka. Middleware
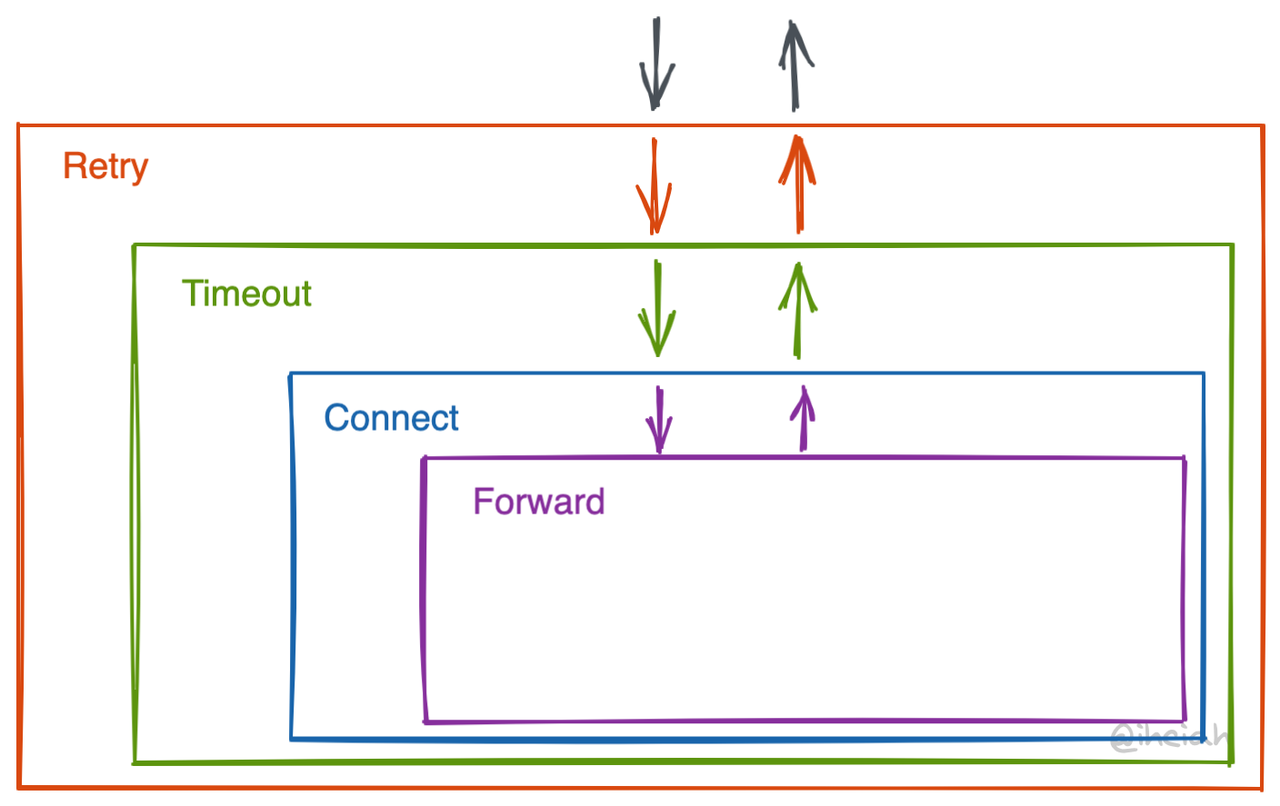
Linkerd2-proxy uses an onion pattern to organize governance logic. The onion pattern provides more freedom, with outer components responsible for calling (or not calling) inner components. The downside is that it’s too free, and it’s hard to align interfaces or constraints between layers on a stage. There are no clear boundaries, and the interfaces are not fixed, which might be frustrating when implementing.
Each layer is generally implemented using Tower Service (detailed in the following sections). Services can be nested, and their wrapping logic also has corresponding abstractions, Layer. Linkerd has even raised a dimension to make assembly easier by creating a NewService trait and corresponding wrapping methods. Ah what is a monad?
It’s hard to explain this part, but you can refer to the Linkerd2-proxy code for specifics, such as linkerd/app/core/svc.rs.
Temporary Data & Configuration
How should Filters or Middleware store temporary states? And what about configurations?
Temporary States
Obviously, Filters/Middleware are stateful, like TLS which needs to store handshake information. Where do those temporary data are stored?
Stored in Context
If we have a connection or request-level Context that each layer passes, we can store temporary quantities in the Context, making the Filter Chain/Middleware stateless and globally available. Whenever a new connection/request comes in, we just need to rebuild a Context (at the same time, we can pool objects).
However, the problem with this approach is that the Context is an unstructured storage, bringing conversion costs and data dependency uncertainty, losing chances for static checks.Stored on Them
Storing data on itself is obviously a better solution than Context. In this case, the Filter Chain/Middleware will no longer be global variables, but stateful entities tied to connections/requests. Currently, Envoy/Mosn follow a similar approach.
Configuration
Here, configuration refers to data fetched from the control plane.
Note: Some details haven’t been finely elaborated.
Connection-Level
Let’s start with connection-level configurations, like whether TLS is enabled.
Handling this is straightforward; when the main thread gets the data update, it pushes the request to the Worker thread. The configuration is stored in the thread’s Thread Local Storage, and when creating a Filter Chain/Middleware, it directly uses this set of configurations. Thus, new connections use the new configuration.
We then need to broadcast a shutdown requirement to old connections, expecting the other side to shut down proactively.
Request-Level
In a long-connection scenario, we hope the configuration can take effect immediately after an update.
- One approach is for the component to directly refer to the Thread Local Storage configuration (high coupling);
- Another is to push updates to the component after the configuration update, and the component updates its internal state;
- Another possibility is to directly create a new Filter Chain/Middleware from the outside, but this requires managing the migration of old states.
Tokio + Tower Ecosystem
Tokio is the de facto standard Runtime in the Rust ecosystem. Tower is a set of abstract Traits and toolkits used in conjunction with Tokio.
Tower Service is a very general service abstraction that can provide asynchronous call abstractions.
1 | pub trait Service<Request> { |
Note that the parameter for call is &mut self, so a single Service cannot be used concurrently but can modify its internal state.
So how do we handle concurrent requests? We clone them. By now, you could write a middling performance implementation, but cloning the Service’s overhead is still there.
However, Service is generally not occupied for long (Service is responsible for creating Future and does not execute it, and Future has no reference relationship with Service), most of the time it’s idle, and not reusing it would be a waste to clone a bunch.
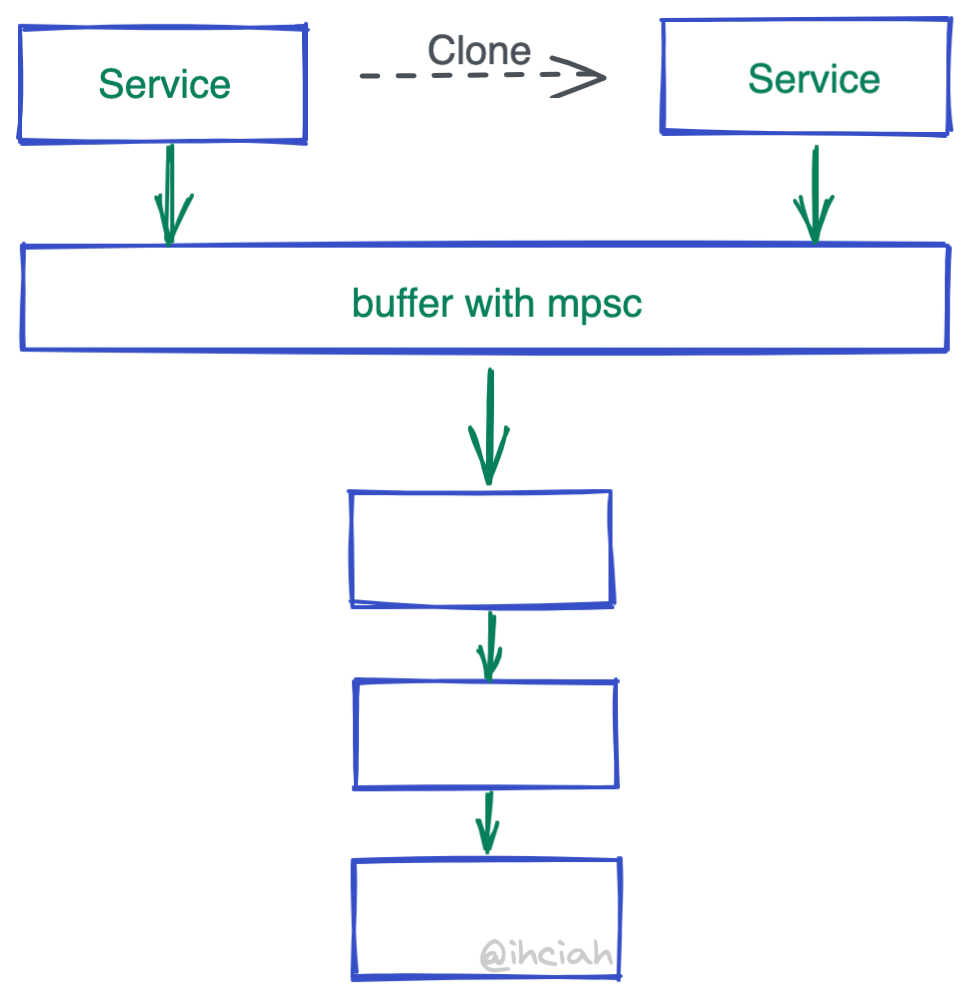
To address this, Tower has something called buffer(). The implementation is very simple—just an mpsc channel. When cloned, it does not clone the inner-layer Service it holds but only the mpsc’s Sender. Who does receive then? A Spawned coroutine will loop and process the received data and call the inner-layer Service.
Another question arises: turning a concurrently callable Service into a serially processed one through a channel certainly reduces cloning, but won’t there be performance issues? The answer is, if the Service is properly implemented, then there will be no performance issues.
Why so? Going back to a previous explanation: after all, Service is just a Future creator; it doesn’t actually execute the Future, and the Future will either be Spawned or awaited, and the Future’s execution does not depend on Service. A properly implemented means ensuring the Future’s creation logic is as light as possible and housing heavier logic within the Future itself.
So in summary, Tower Service creates Future with light logic, so they are often processed serially through buffer, and the Future created by Service is unrelated to Service, allowing Tokio to schedule Future on idle cores to maximize CPU usage.
Thread-per-core Runtime + Forked Tower
So beautiful—use Tokio + Tower, right? In fact, in some scenarios, it’s not so rosy, such as in proxy scenarios.
Is Fair Scheduling Necessary?
If we assume that all logic is light and relatively balanced, the necessity of Tokio’s fair scheduling disappears. This is applicable in Service Mesh scenarios.
Note: The cost of fair scheduling itself is not small (refer to Go’s scheduler for this), and the created Future must be Send + Sync (easily understood since they might be scheduled on different cores), which requires all internal qualities of the Future to be Send + Sync, effectively blocking the possibility of using Thread Local Storage in components, either Atomic or Lock.
If we give up fair scheduling and go with a libevent-like model, we can let go of the Send + Sync constraint and eliminate the overhead of cross-thread scheduling.
Wanting to be forward-thinking, I made a Runtime (Github), based on io-uring, implementing a thread-per-core model Runtime, and enabled Rust’s GAT feature. Compared to Tokio and Glommio, which had similar intentions, it has a significant performance edge (like on an 8-core physical machine, it can reach 1.6 million QPS in a 100K echo scenario, while Tokio is less than 800k and Glommio is about 1.2 million).
Is Cloning While Creating the Future Necessary?
Previously mentioned, the Future created by Service is static, unrelated to the Service itself. So what if the Future needs to use temporary quantities inside the Service? The current method is through Arc, and for a single component, the cost of Arc cannot be overlooked.
Let’s reconsider the Tower abstraction:
- What problem did the ready interface solve?
Through the ready method, we can probe the service’s availability because it doesn’t need to consume the Request. We believe this need is limited, and it can be achieved in other ways; while the complexity and computing cost brought by ready is considered high (partly because of the enabling of GAT). - Does the Future returned by the call have to be static?
Through GAT, we can add lifetime marks to the associated types in Trait. This can tie the Future to the Service that created it, forming a reference relationship and avoiding the shared overhead of Arc/Rc.
Our modification looks very favorable, almost eliminating all unnecessary overheads. However, because the Future is now tied to Service, it must also capture the Service’s reference during execution. Since call needs &mut self, this Future will affect the use of Service—that is to say, Service can no longer be shared for serial use. We must create a new Service for a specific connection, and this Service can only be used by one Future at a time.
Fortunately, this constraint is acceptable in proxy scenarios. For long connections, the cost of creating Service and sharing Service & shared internal Service quantities can be considered negligible; for short connections, we can achieve not too shabby performance by reusing Service.
To sum it up: The modified Service abstraction only retains the call method, and the Future it generates is related to self, avoiding the shared overhead of Arc/Rc. But it also confines Service to non-shared use, which is acceptable.