This article also has a Chinese version.
This series of articles mainly introduces how to design and implement a Runtime based on the io-uring and Thread-per-core model.
Our final Runtime product Monoio is now open source, and you can find it at github.com/bytedance/monoio.
- Rust Runtime Design and Implementation - General Introduction
- Rust Runtime Design and Implementation - Design Part 1
- Rust Runtime Design and Implementation - Design Part 2
- Rust Runtime Design and Implementation - Component Part
- Rust Runtime Design and Implementation - IO Compatibility Part
This article is the first in the series, mainly introducing some general concepts as well as writing a very simple Runtime as an example.
UPDATE: Here is a presentation video I made(in Chinese), and the corresponding PPT. Interested viewers are welcome to watch the playback :)
Parallelism & Concurrency
Parallelism is not the same as concurrency.
For example, let’s say I want to check the availability of 10 URLs as quickly as possible:
- The most naive way is to request them serially, which can be handled in a simple loop. However, it is clear that neither our CPU nor network card are fully utilized, and since there is no dependency between multiple URLs, theoretically, it could be faster.
- We might create a thread pool to tackle this task. If there happen to be enough available threads in the pool, we can directly distribute these 10 tasks and execute them in parallel. Parallelism means having multiple computing resources (which could be CPUs or threads as independent computing resources), and each task exclusively occupies one. So, in the dimension of threads, we can consider these tasks to be parallel.
- We can also create 10 Tasks for those URLs and execute them asynchronously within a Runtime. Our Runtime could be single-threaded, so how does it accelerate the process? Because these Tasks do not continuously monopolize resources. When IO blocking occurs, the thread relinquishes control, leaving it available for other tasks. These tasks are concurrent.
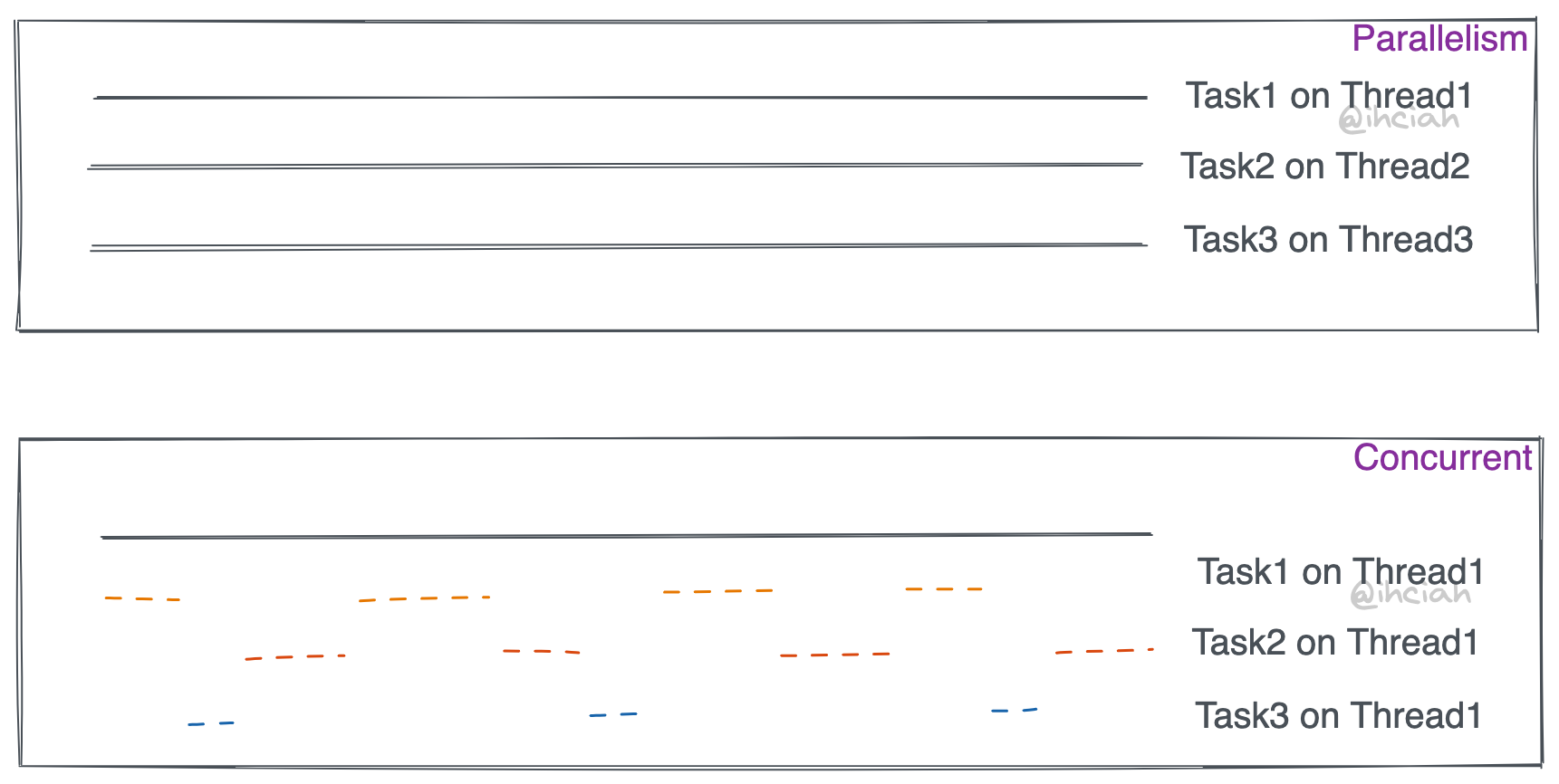
As can be seen, the focus of parallelism is on simultaneity and exclusivity, while the focus of concurrency is on the pseudo-simultaneous execution at the task level, allowing them to share computing resources.
epoll & io-uring
To achieve the “concurrency” mentioned earlier, we need support from the kernel.
epoll
There are countless articles about epoll, so let’s just briefly mention it here: epoll is a better IO event notification mechanism under Linux that allows for monitoring the readiness of multiple file descriptors concurrently.
It mainly includes 3 syscalls:
epoll_create
This creates an epoll file descriptor (fd).epoll_ctl
This is used to add, modify or remove the fd events monitored by the epoll fd.epoll_wait
This waits for monitored fd events and returns as soon as any event occurs; it also supports passing a timeout, so even without any ready events, it can return after the timeout has elapsed.
If you don’t use mechanisms like epoll, and directly make syscalls instead, you would need to have your fds in blocking mode (the default), so when you want to read from an fd, the read would block until there is data available.
When using epoll, you need to set the fd to non-blocking mode. When you read, if there is no data, it will immediately return WOULD_BLOCK. The next step is to register this fd to the epoll fd and set the EPOLLIN event.
Afterward, when there’s nothing else to do (all tasks are stuck on IO), you fall into the syscall epoll_wait. Once an event returns, you can then read from the corresponding fd (depending on the trigger mode you set when registering, you might need to do some additional stuff to ensure the next read goes smoothly).
In summary, this mechanism is quite simple: set the fd to non-blocking and register it to the epoll fd when needed. When the epoll fd event triggers, then perform operations on the fd. This way, the blocking of multiple fds is transformed into the blocking of a single fd.
io-uring
Different from epoll, io-uring is not an event notification mechanism, it is a true asynchronous syscall mechanism. You do not have to make syscalls manually after notification, because it has already been taken care of for you.
io-uring is primarily made up of two rings (SQ and CQ), with SQ used to submit tasks and CQ used to receive notifications of task completion. Tasks (Ops) can often correspond to a syscall (such as ReadOp corresponding to read), and will also specify the parameters and flags for that syscall.
When submitting, the kernel consumes all SQEs and registers callbacks. Later, when data becomes available, such as when a network interrupt occurs and data is read in through the driver, the kernel triggers these callbacks to do what the Ops wanted, like copying data from an fd to a buffer (this buffer is user-specified). Compared to epoll, io-uring is purely synchronous.
Note: This section refers to io-uring with FAST_POLL.
In summary, in terms of usage, io-uring and epoll are pretty similar: normally, you throw what you want to do into the SQ (and submit if the SQ is full), and then perform submit_and_wait(1) when there’s nothing else to do (all tasks are stuck on IO) (submit_and_wait and submit are not syscalls, they are liburing’s wrappers for enter). After returning, you consume the CQ, and that’s how you get the syscall results. If you are more concerned about latency, you can be more aggressive with submit, pushing tasks early so that you can return as soon as the data is ready, but at the same time, you pay the price of increased syscalls.
The Execution Flow of Asynchronous Tasks
In conventional programming, our code’s control flow corresponds to its thread. Similar to what you would expect in C, your code directly compiles to assembly instructions, which are then executed by a “thread” provided by the operating system, without any additional inserted logic.
Taking epoll as an example, asynchronous programming based on epoll essentially represents multiplexing of threads. Thus, conventional code following a pattern like this cannot be used in such scenarios:
1 | for connection = listener.accept(): |
Because the accept call in this block of code needs to wait for IO, directly blocking here would cause the thread to block, preventing it from executing other tasks.
Callback-Based Programming
Libevent, commonly used in C/C++, is based on this model. The user code relinquishes control (since there is only one thread control, and there are numerous user tasks) and instead operates by registering Callbacks to libevent, associated with certain events. When an event occurs, libevent will call the user’s callback function and pass the event’s parameters to the user. After setting up some callbacks, users hand over control of the thread to libevent. Internally, libevent helps manage interactions with epoll and executes callbacks when they are ready.
While this method is efficient, the programming can be quite cumbersome. For example, if you want to make an HTTP request, you need to split the operation into several synchronous functions and link them together via callbacks: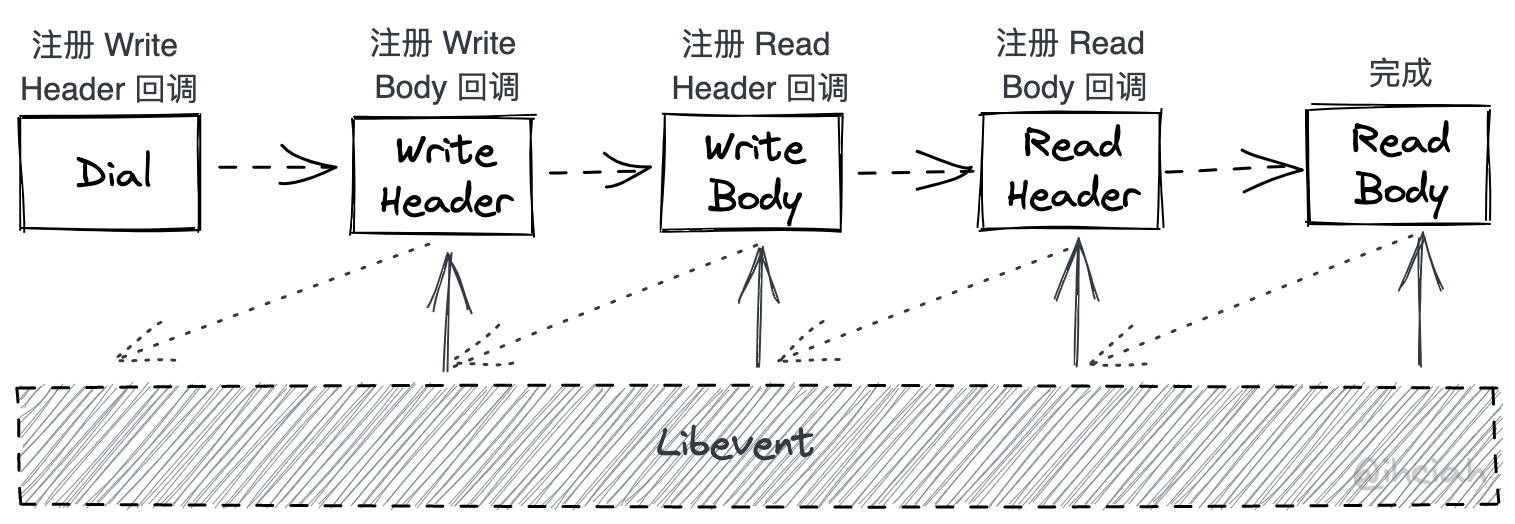
What could initially be aggregated within a single function gets split into a bunch of functions. Compared to procedural programming, stateful programming is much more chaotic and prone to issues due to overlooked details by the programmer.
Stackful Coroutines
What if we could insert some logic between the user code and the final product? Like Go, in Golang the user code actually corresponds to scheduled goroutines, while the actual thread control is held by the go runtime. Goroutines can be scheduled by the runtime and are preemptible during execution.
When a goroutine needs to be interrupted and switched to another goroutine, the runtime simply modifies the current stack frame. Each goroutine’s stack is actually on the heap, so it can be interrupted and restored at any time.
The networking libraries also match this set of runtimes. The syscalls are non-blocking and can automatically be suspended on netpoll.
Stackful coroutines with the runtime decouple the relationship between the Task level user code and the thread.
Stackless Coroutines Based on Futures
The context switch overhead of stackful coroutines should not be ignored. Because it can be interrupted at any time, it is necessary to save the current register context; otherwise, the scene cannot be restored when resumed.
Stackless coroutines do not have this problem, and this model fits very well with the concept of Rust’s Zero Cost Abstractions. Rust’s async + await fundamentally unfolds the code automatically, with async + await code expanding into a state machine based on llvm generator; the state machine implements Future to interact with the runtime through the poll method (for more details, see this article).
Fundamentals of Rust’s Asynchrony Mechanism
The design of Rust’s asynchrony mechanism is complex, with the standard library interfaces and Runtime implementation being decoupled.
Rust’s asynchrony relies on the Future trait.
1 | pub trait Future { |
How are Futures executed? As implied by the above trait definition, it’s through the poll method. The result returned is Poll, which can either be Pending or Ready(T).
Then who calls the poll method?
- The user. Users can manually implement Future, and if for instance they wrap a Future, they obviously need to implement
polland callinner.poll. - The Runtime. Runtime is the ultimate caller of
poll.
As an implementer of Future, you must ensure that once Poll::Pending is returned, the Future that depends on the IO readiness in the future can be awoken. A Future is awoken through the Waker within the Context. As to what happens after a Future is woken, it is implemented by the provided cx of Runtime (like adding this Task to a pending execution queue).
Therefore, anything that produces an event is responsible for storing the Waker and waking it when Ready; the entity providing the cx receives the wakeup operation and is responsible for rescheduling it. These two concepts correspond to the Reactor and Executor, respectively, and they are decoupled by the Waker and Future.
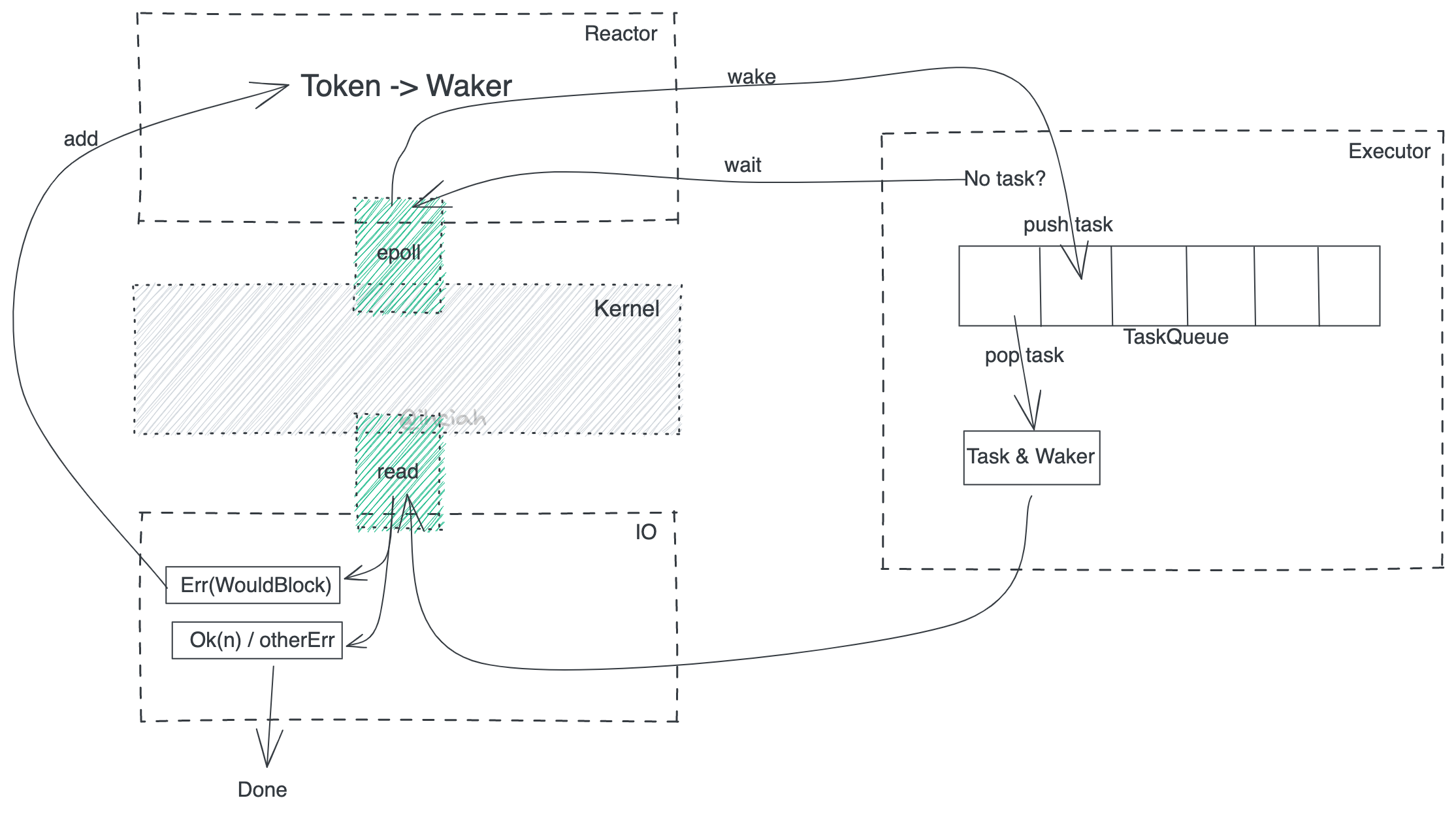
Reactor
For example, you could even implement your own custom Reactor on top of Tokio (which is roughly equivalent to creating your own multiplexing system). In fact, this is exactly what Tokio-uring does: It registers a uring fd with Tokio (mio), and then based on that fd and its own system for managing pending operations, it exposes event source capabilities as a Reactor. In tokio-tungstenite, the problem of read/write wakeup is also addressed through WakerProxy.
Another example is a timer driver. Clearly, signals for IO events come from epoll/io-uring, etc., but timers are different. Internally, they maintain structures like timing wheels or N-ary heaps, so waking up the Waker is definitely the responsibility of the Time Driver, and thus it needs to store the Waker. In this sense, the Time Driver is an implementation of a Reactor.
Executor
Having discussed the Reactor, let’s introduce the Executor. The Executor is responsible for task scheduling and execution. Taking the Thread-per-core scenario as an example (and why this example? Because it’s so simple without cross-thread scheduling), it can be implemented as a VecDeque. The job of the Executor is to fetch tasks from it and call their poll methods.
IO Components
At this point, you might be curious, since the Reactor is responsible for waking up the corresponding Task and the Executor is responsible for executing the awakened Task, let’s look at the source - who is responsible for registering the IO with the Reactor?
The IO library (such as the implementation of TcpStream) is responsible for registering IO operations that cannot be completed immediately with the Reactor. This is also one reason why, when using Tokio, you must use Tokio::net::TcpStream instead of the standard library’s version; and why you need to use the Runtime’s sleep method when you want to asynchronously sleep.
Implementing a Minimalist Runtime
For simplicity’s sake, we will use epoll to write this Runtime. This is not our final product, but merely a demonstration of how to implement the simplest possible Runtime.
The complete code for this section is available at github.com/ihciah/mini-rust-runtime.
Corresponding to the three main components discussed earlier: Reactor, Executor, and IO Components, we will implement each. Let’s start with the Reactor.
Reactor
Since directly handling epoll can be somewhat cumbersome, and as the focus of this article is not the Rust Binding, we will use the polling crate to facilitate epoll operations.
The basic use of the polling crate involves creating a Poller and adding or modifying file descriptors (fds) and their interests in the Poller. By default, this package uses oneshot mode (EPOLLONESHOT), where you need to re-register after an event is triggered. This might be useful in a multi-threaded scenario, but it seems unnecessary in our simple single-threaded version, as it would result in additional epoll_ctl syscall overhead. However, for the sake of simplicity, we will still use it.
As a Reactor, when we register an interest in the Poller, we need to provide an identifier corresponding to that interest. This identifier is often referred to as a Token, UserData, or Key in other contexts. When an event is ready, this identifier is returned as-is.
So the things we need to do are roughly:
- Create a
Poller. - When we need to monitor an fd for Readable or Writable events, we add an interest event to the
Pollerand store the corresponding Waker. - Before adding an interest event, we need to allocate a Token so that, when the event is ready, we know where to find the corresponding Waker.
Thus, we can design our Reactor to be:
1 | pub struct Reactor { |
In other Runtime implementations, a slab is often used, which handles both Token allocation and Waker storage.
For simplicity, here we use a HashMap to save the relationship between Tokens and Wakers. A somewhat tricky part is storing the Waker: since we are only concerned with reads and writes, we define the MapKey for a read as fd * 2 and the MapKey for a write as fd * 2 + 1 (because TCP connections are full-duplex, read and write operations on the same fd are unrelated and can occur in different Tasks, each with its own independent Waker); meanwhile, the UserData (Token) for an event still uses the fd itself.
1 | impl Reactor { |
Attaching or detaching an fd to the Poller is also quite straightforward:
1 | impl Reactor { |
One thing to note is that before attaching it, you need to set it to Nonblocking mode; otherwise, if there is a spurious wakeup during a syscall (epoll does not guarantee that there won’t be spurious wakeups), it could cause the thread to block.
We then face a question: when do we call epoll_wait? The answer is when there are no tasks available. If all tasks are waiting for IO, then we can safely fall into a syscall. Therefore, our Reactor needs to expose a wait interface for the Executor to wait when there are no tasks to execute.
1 | pub struct Reactor { |
When receiving syscall results, you need to provide a pre-allocated buffer (Vec<Event>). To avoid allocating this buffer every time, we directly save it in the structure and use Option to temporarily take ownership of it.
The wait operation needs to do the following:
- Enter the syscall.
- After returning from the syscall, process all ready Events. If the event is readable or writable, then find and remove the corresponding Completion from the HashMap, and wake it up (the rule for the correspondence between the fd and the Map Key was mentioned earlier: readable corresponds to
fd * 2, writable corresponds tofd * 2 + 1).
Finally, complete the creation function for the Reactor:
1 | impl Reactor { |
At this point, our Reactor is complete. Broadly speaking, it’s a wrapper around epoll, with additional handling for the storage and waking up of Wakers.
Executor
The Executor needs to store Tasks and execute them.
Task
What is a Task? A Task is actually a Future, but since Task needs shared ownership, we use an Rc to store it here. We know that users contribute a Future without knowing its exact type, so we need to put it in a box, and we use LocalBoxFuture for that. Also, because we need interior mutability, the definition of Task is as follows:
1 | pub struct Task { |
TaskQueue
We design a storage structure for Tasks, and for simplicity, we directly use VecDeque.
1 | pub struct TaskQueue { |
This TaskQueue needs to be able to push and pop tasks:
1 | impl TaskQueue { |
Waker
The Executor needs to provide a Context that includes a Waker. A Waker needs to be able to enqueue a task for execution when it is woken up.
1 | pub struct Waker { |
A Waker implements dynamic dispatch through a raw pointer and a vtable. So we have two things to do:
- Obtain the pointer to the Task structure and maintain its reference count.
- Generate the corresponding
vtablefor the type.
We can define the vtable like this:
1 | struct Helper; |
Manually managing the reference count: We will use Rc::into_raw to get the raw pointer of Rc<Task> and use it with the vtable to construct a RawTask and then build a Task. In the implementation of the vtable, we need to carefully manage the reference count manually: for example, when clone_waker, although we’re only cloning a pointer, it implies a copy semantically, so we need to manually increment the reference count.
The Task implements wake_ and wake_by_ref_ to reschedule the task. Rescheduling a task involves simply obtaining the executor from the thread local storage and then pushing it to the TaskQueue.
1 | impl Task { |
Executor
With the previously mentioned components in place, constructing the Executor is quite straightforward.
1 | scoped_tls::scoped_thread_local!(pub(crate) static EX: Executor); |
当用户 spawn Task 的时候:
1 | impl Executor { |
What it actually does is box the incoming Future, then constructs an Rc<Task> and throws it into the execution queue.
So where is the main loop of the Executor? We can put it in the block_on method.
1 | impl Executor { |
This section is a bit complex and can be broken down into the following steps:
- Create a
dummy_wakerthat essentially does nothing. - (in loop) Poll the incoming future, check if it’s ready, and if it is, return and end the
block_on. - (in loop) Loop through all the Tasks in the
TaskQueue: construct their correspondingWakerand then poll each Task. - (in loop) At this point, there are no tasks left to execute, which could mean that the main future is ready, or it could be that all are waiting for IO. So, check the main future again, and if it’s ready, return.
- (in loop) Since everyone is waiting for IO, the next step is to
reactor.wait(). At this point, the reactor will enter a syscall to wait for at least one IO operation to be ready, then it will wake the corresponding Task, which will push tasks back into theTaskQueue.
With this, the Executor is essentially complete.
IO Components
The IO components need to hang themselves on the Reactor when they would block. Taking TcpStream as an example, we need to implement tokio::io::AsyncRead for it.
1 | pub struct TcpStream { |
When creating a TcpStream, it needs to be registered with the Poller, and should be deregistered when it is destroyed:
1 | impl From<StdTcpStream> for TcpStream { |
When implementing AsyncRead, perform a read syscall on it. Since the file descriptor (fd) is set to non-blocking mode when it’s added to the Poller, the syscall here is safe.
1 | impl tokio::io::AsyncRead for TcpStream { |
The read syscall may return a correct result, or it may return an error. Among the possible errors, WouldBlock requires special handling. When WouldBlock is encountered, we need to suspend the operation on the Reactor. This is indicated through our previously defined function modify_readable, demonstrating our interest in readability events. After the Reactor suspension action is completed, we can confidently return Poll::Pending, because we know that it will be woken up later on.
This article has provided a primer on basic concepts such as concurrency, epoll, io-uring, and briefly compared different programming models, including callback-oriented programming, stackful coroutine model, and the Future abstraction. Furthermore, it offered an in-depth interpretation of Rust’s asynchronous model. Finally, based on epoll, we incrementally wrote an extremely simple Runtime.
In the next chapter, I will introduce the model of Monoio, event driving, IO interfaces, and some considerations and thoughts during the design process.