This article also has a Chinese version.
This series of articles mainly introduces how to design and implement a Runtime based on the io-uring and Thread-per-core model.
Our final Runtime product Monoio is now open source, and you can find it at github.com/bytedance/monoio.
- Rust Runtime Design and Implementation - General Introduction
- Rust Runtime Design and Implementation - Design Part 1
- Rust Runtime Design and Implementation - Design Part 2
- Rust Runtime Design and Implementation - Component Part
- Rust Runtime Design and Implementation - IO Compatibility Part
This article is the fifth in the series. Originally, the series concluded with four articles, but with the recent addition of epoll support (!73), I decided to write about the design of this part as well.
Previously, Monoio only supported io_uring, but distributing binary applications externally or deploying them on a large scale within the company both require a higher version of the kernel. Upgrading the kernel version within ByteDance is often a lengthy process, and it is even more challenging to guarantee the kernel version of external users.
Therefore, we want to provide support for legacy IO drivers. Instead of existing industry solutions, we plan to offer this as a seamlessly transparent form of support: users or frameworks continue using an io_uring-like mode to operate IO (i.e., our AsyncReadRent/AsyncWriteRent), while the runtime internally detects the current environment’s support and falls back if necessary.
In other words, users only need to write one set of code without worrying about compatibility issues (current other open-source solutions are strongly bound to either io_uring or epoll, as well as the corresponding programming patterns and APIs, which cannot achieve seamless migration and backward compatibility with lower version environments).
The Right Way to Use epoll
The legacy io driver in Linux is, of course, epoll.
This was briefly introduced in the first article of this series. In our example, we used the polling crate, whose epoll implementation employs the oneshot mode. As the name suggests, oneshot triggers only once, so it must be re-added with a syscall each time it is needed after use. Often, we need to perform multiple operations on the same fd, so this one-time readiness notification is clearly not very economical.
Mio, a more widely used poll wrapper library, employs the much more efficient edge-triggered mode. In this mode, the fd and its corresponding interests only need to be registered once, and epoll_wait is only notified when the IO’s readiness state changes from not ready to ready.
Of course, a trade-off is inherent as in this mode we have to maintain the readiness state at the user level. Although this topic is almost a standard interview question for new college graduates, it’s worth mentioning briefly. For instance, if we rely solely on the kernel’s notification, we have to either exhaust the IO at once, or we might never get notified by the kernel about the IO being ready again after a certain operation. Therefore, we need to keep track internally and proceed with the corresponding syscall without waiting if the IO is already ready.
Mio is essentially a low-level cross-platform polling encapsulation, and it does not maintain the IO readiness state mentioned earlier; this state maintenance needs to be handled by the upper-level runtime.
Let’s use Tokio as an example to briefly analyze both the registration and operation processes of IO.
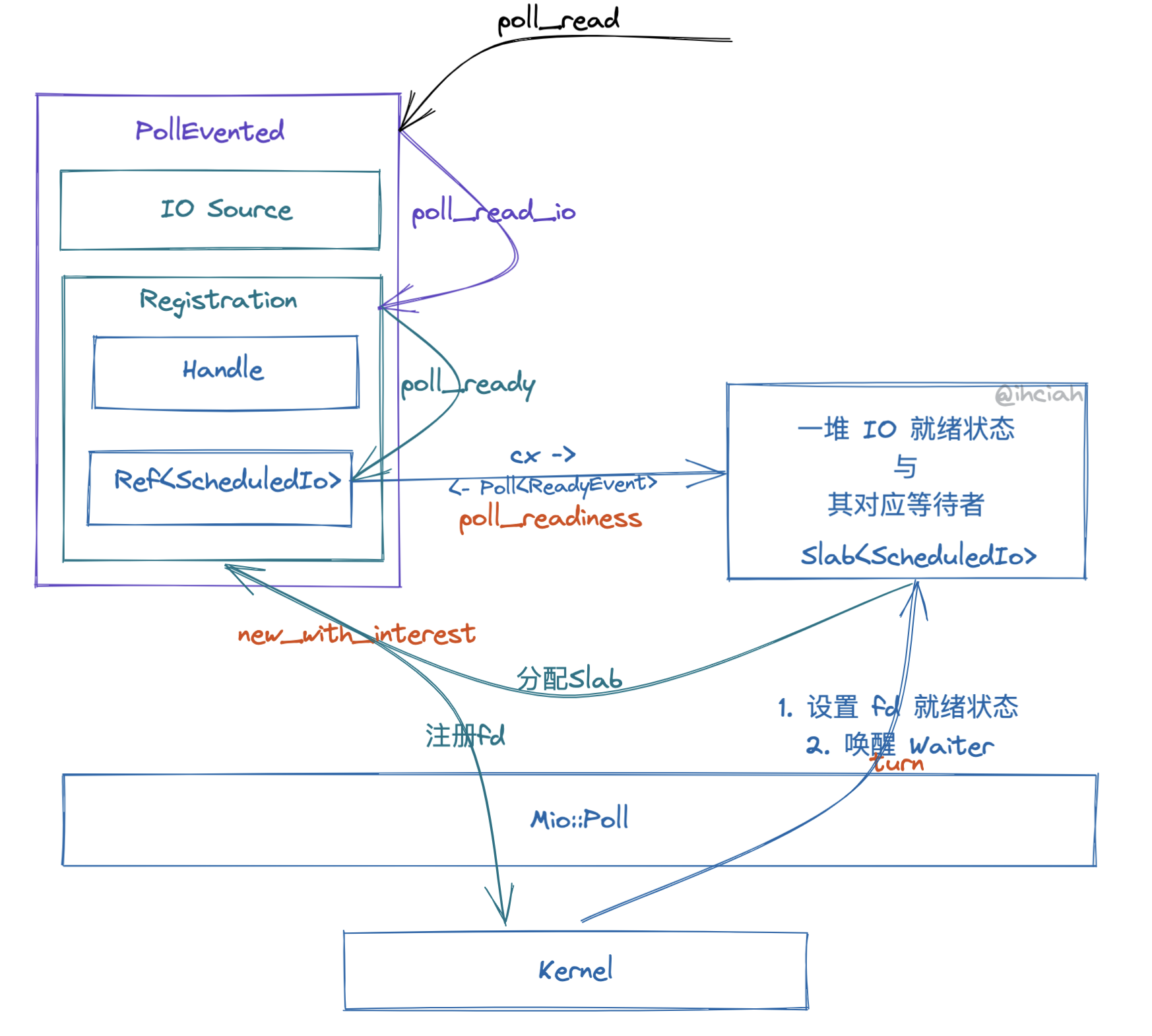
IO Registration
When creating an IO, such as a TcpListener accepting an fd, this fd will be wrapped as a TcpStream. Inside the TcpStream is a structure called PollEvented, and many user-facing structures (such as UnixStream, etc.) are merely wrappers around PollEvented.
PollEvented is registered with the fd and its interests upon creation and is unregistered upon dropping. The IO readiness state and waiters are managed within a unified Slab (corresponding to the concept of Registration). The PollEvented structure internally contains io and registration information; the registration information in turn holds a Driver Handle and a Ref<ScheduledIo>.
When PollEvented is created, it gets the current Driver’s Handle from TLS and registers its interests. During registration, the driver internally allocates space in the Slab to store its status information (i.e., ScheduledIo) and records the index of that status in the Slab in the returned registration information.
IO Operations
Through PollEvented, Tokio can provide implementations of the methods poll_read and poll_write for other upper-layer network wrappers.
The core code implementation of poll_read is as follows:
1 | let n = ready!(self.registration.poll_read_io(cx, || { |
It passes the read method as a closure to poll_read_io to be processed:
1 | loop { |
poll_read_io internally mainly does two things:
Wait for the fd to be ready
Perform IO
- If IO returns WOULD_BLOCK, then clear the ready status in the registration information (
Ref<ScheduledIo>) and continue looping.
- If IO returns WOULD_BLOCK, then clear the ready status in the registration information (
The main difficulty lies in poll_ready, which in turn calls poll_readiness.
The poll_readiness code is quite complex, with complexities primarily in addressing cross-thread synchronization issues. Its atomic operations contain both Generation and Tick information and perform a CAS while verifying and modifying them. Generation is globally incremented to mark threads; Tick is thread-level to indicate different rounds of epoll wait. These mechanisms ensure that when an fd is operated on across threads, signals are not missed.
However, since our Runtime itself is not designed to support such operations, this is not expanded on here. In summary, Tokio’s operation on IO only has the ability to sense readiness within the driver, and the execution of the IO syscall is left to the network component itself.
Compatibility Plan
We need a driver based on epoll (mio) to expose the same interfaces as an io_uring based driver.
Mock io_uring Approach
Because io_uring = wait for readiness + execute; and epoll only has the capacity to wait for readiness, a very straightforward idea might be to complement these capabilities by executing syscalls ourselves. Why not “simulate” an io_uring based on Mio and expose io_uring style interfaces?
A runtime based on epoll, such as Tokio, only needs to sense the readiness event, set the fd to ready, and wake the tasks with the corresponding Interest. Our simulated io_uring would perform syscalls on top of this and then wake the tasks.
Each fd would correspond to an attached structure, which includes:
Read and write queues (separate, two independent queues):
- When epoll senses that the fd is ready, it sets the fd’s ready status, executes the syscall, and wakes the task in the queue.
- In addition to storing the waker waiting on it, it also needs to store the task itself, as we need to execute the syscall for the user, and only wake the task after the syscall has succeeded.
Ready status: New read and write requests in the queue can decide whether to execute the syscall directly or place themselves in the read or write queue based on this status.
This approach requires us to abstract the access pattern of io_uring, rather than our current direct access to io_uring.
Considering that this part actually involves considerable redundant encapsulation and matching overhead, it was not adopted.
OpAble Solution
An Op structure (such as Connect, which specifies an fd and OsSocketAddr) creates an io_uring entry on its own, so could we extend this implementation into a Trait that allows Op to decide how to interface with epoll?
Let’s think about it. With io_uring, structures like Connect (hereafter referred to as Op, because it represents an Operation) only need to generate an Entry. Afterwards, the driver internally pushes it into the SQ, and what is consumed from the CQ is a generic representation, including user_data, result, and a flag. Internally, the driver only needs to use user_data to locate this task in the state storage Slab and set the status to wake the waiter.
Under epoll, the basic unit is no longer “task” but rather io. Io includes its corresponding readiness state, the reading waiters waiting for it, and the writing waiters. After the driver senses a ready event through epoll_wait, it needs to use the user_data from that event to locate the io in the Slab, update its ready status, and decide whether to wake the reading and writing waiters based on the ready status in that event.
After waking the waiter, it is also necessary to execute the io syscall. There are actually 3 schemes for this:
- Internal implementation, internal execution -> corresponds to the simulated io_uring approach mentioned earlier
- External implementation, internal execution -> the current approach, in which the external Op provides the specific syscall execution function in the form of implementing OpAble
- External implementation, external execution -> an approach used by runtimes such as Tokio, where the driver exposes
poll_readiness, and the specific executor makes the syscall themselves, and after the syscall returns, it determines whether it isWOULD_BLOCK. If it is, it is necessary to set the readiness within the runtime (as shown in thenet/TcpStreamimplementation)
Compared to approach 1, this approach gives Op greater freedom (although it’s not actually that useful, it can save some encapsulation), which can be used to implement behaviors like async fn ready() (no syscall necessary, which is decided by Op’s own implementation); it can also save some match comparison overhead (a cost brought by encapsulation).
Compared to approach 3, executing the syscall within the driver can save the necessity of the WOULD_BLOCK check (repetitive code, which every component has to write), and secondly, it shields the component from the difference between io_uring and epoll because in this approach, both epoll and io_uring directly return syscall results to the component.
1 | pub(crate) trait OpAble { |
In this approach, components (such as net/TcpStream) only perceive Op (not aware of the differences between io_uring/epoll); Op implements both the io_uring and epoll behaviors (as a runtime providing transparent compatibility, of course, they all need to be implemented); the different drivers employed by the runtime after starting will call different Op behaviors.
An example of a Op implementation (this example moved part of the code from mio, and its implementation itself does not involve io_uring/epoll determination):
1 | /// Accept |
IO Registration Issue
Don’t forget, using epoll requires.fd and interests to be registered in advance, and the readiness state to be managed internally, not as simple as io_uring, where you can just throw a task into it.
The network component’s holding of an fd is actually holding a SharedFd (its main design purpose is to maintain the fd’s open status after the io_uring entry has been pushed into the kernel). When a SharedFd is created, we can determine whether to register it internally based on the current io driver type, and likewise, we will unregister it when it is dropped.
The management of the readiness state and waiters is still handled by the Slab for efficient O1 search and deletion.
Capability Exposure
We support both Legacy and Uring io drivers, but how do we expose them for users to use?
First, we expose a feature using conditional compilation to eliminate branches that users do not want (for example, when a user specifies that they want either uring or legacy). Secondly, through macro parameters or builder parameters, we allow users to specify the driver at runtime.
In addition, we offer a FusionDriver, which automatically detects the platform’s support capabilities and chooses the appropriate driver. By default, using #[monoio::main] will use this behavior, making it convenient for users with different platforms and kernel versions to launch successfully.