This article also has a Chinese version.
This series of articles mainly introduces how to design and implement a Runtime based on the io-uring and Thread-per-core model.
Our final Runtime product Monoio is now open source, and you can find it at github.com/bytedance/monoio.
- Rust Runtime Design and Implementation - General Introduction
- Rust Runtime Design and Implementation - Design Part 1
- Rust Runtime Design and Implementation - Design Part 2
- Rust Runtime Design and Implementation - Component Part
- Rust Runtime Design and Implementation - IO Compatibility Part
This article is the third in the series, continuing the discussion on design trade-offs for the runtime environment.
Time Driver Design
Many scenarios require timers, such as timeouts or needing to select between two futures, where one is a timeout. As a runtime, it must support asynchronous sleep.
Timer Management and Waking
The internal implementation for Glommio is relatively simple; it directly uses a BTreeMap to maintain a mapping of Instant -> Waker. Every time the current time is used to perform a split_off to fetch all expired timers, wake them up, and calculate the interval until the next wake. This interval is then passed in when the driver parks. Similarly, Tokio also has its own implementation of a timing wheel, which is more complex but also more efficient (although it is less precise than Glommio’s implementation).
Considering our commitment to performance-oriented implementation, we choose a timing wheel approach similar to Tokio’s.
Integration with Driver
Under epoll, before we wait, we need to check the nearest timer. If there is one, we must pass its timeout event as a parameter to wait. Otherwise, if no IO is ready during this time, we will miss the timer’s expected wake-up time. For example, if the user wants a timeout of 100ms, it might end up being 200ms before awakening, which defeats the purpose.
Internally, Tokio has managed this by using EPOLL and a timing wheel. EPOLL serves as the IO Driver, and on top of this, there’s a Timer Driver. Before the Timer Driver falls into the syscall, it calculates the closest event interval from the timing wheel and uses it as a parameter for epoll wait.
Why not use TimerFd to leverage epoll capabilities directly? Because doing so is a bit heavy: creating timerfd, adding and removing it with epoll_ctl are all syscalls, and they can’t perform the coarse-grained merging that timing wheels can.
However, io-uring’s enter does not support passing a timeout (at least not until 5.11, where it became supported through enter arguments). We can only push a TimeoutOp to the SQ to achieve this.
Solution 1
When inserting an element into a slot of the timing wheel, push a TimeoutOp; and when the number in that slot is reduced to zero, push a TimeoutRemoveOp (this cancel operation could be omitted, but there would be a cost of an additional false wake-up).
For example, if we were to create five 10ms timeouts, they would be inserted into the same slot of the timing wheel. At the moment when the count in this slot changes from 0 to 1, we push a 10ms TimeoutOp to the SQ.
Solution 2
Before each wait, calculate the nearest timeout, push it to the SQ, then wait; in the TimeoutOp, set the offset to 1.
Here’s an explanation of what the offset parameter means: simply put, the TimeoutOp will be completed when $offset number of CQ entries are done, or when a timeout occurs.
This command will register a timeout operation. The addr field must contain a pointer to a struct timespec64 structure, len must contain 1 to signify one timespec64 structure, timeout_flags may contain IORING_TIMEOUT_ABS for an absolute timeout value, or 0 for a relative timeout. off may contain a completion event count. A timeout will trigger a wakeup event on the completion ring for anyone waiting for events. A timeout condition is met when either the specified timeout expires, or the specified number of events have completed. Either condition will trigger the event. If set to 0, completed events are not counted, which effectively acts like a timer. io_uring timeouts use the CLOCK_MONOTONIC clock source. The request will complete with -ETIME if the timeout got completed through expiration of the timer, or 0 if the timeout got completed through requests completing on their own. If the timeout was cancelled before it expired, the request will complete with -ECANCELED. Available since 5.4.
This requires pushing the SQ before each wait. The advantage is that there’s no need for a remove (as it’s consumed upon return), avoiding false wake-ups; plus, the implementation is simple, without needing to maintain the Op’s user_data field for pushing TimeoutRemoveOp.
Solution 3
Similar to solution 2, but with the offset set to 0 in the TimeoutOp.
This is more complicated to implement because offset = 0 means it is a pure timer, independent of the number of completed CQs, and it will only complete when the actual timeout occurs. This means we need to either push a TimeoutRemoveOp or bear the cost of a false wake-up (Glommio adopted a similar strategy, choosing to bear this cost).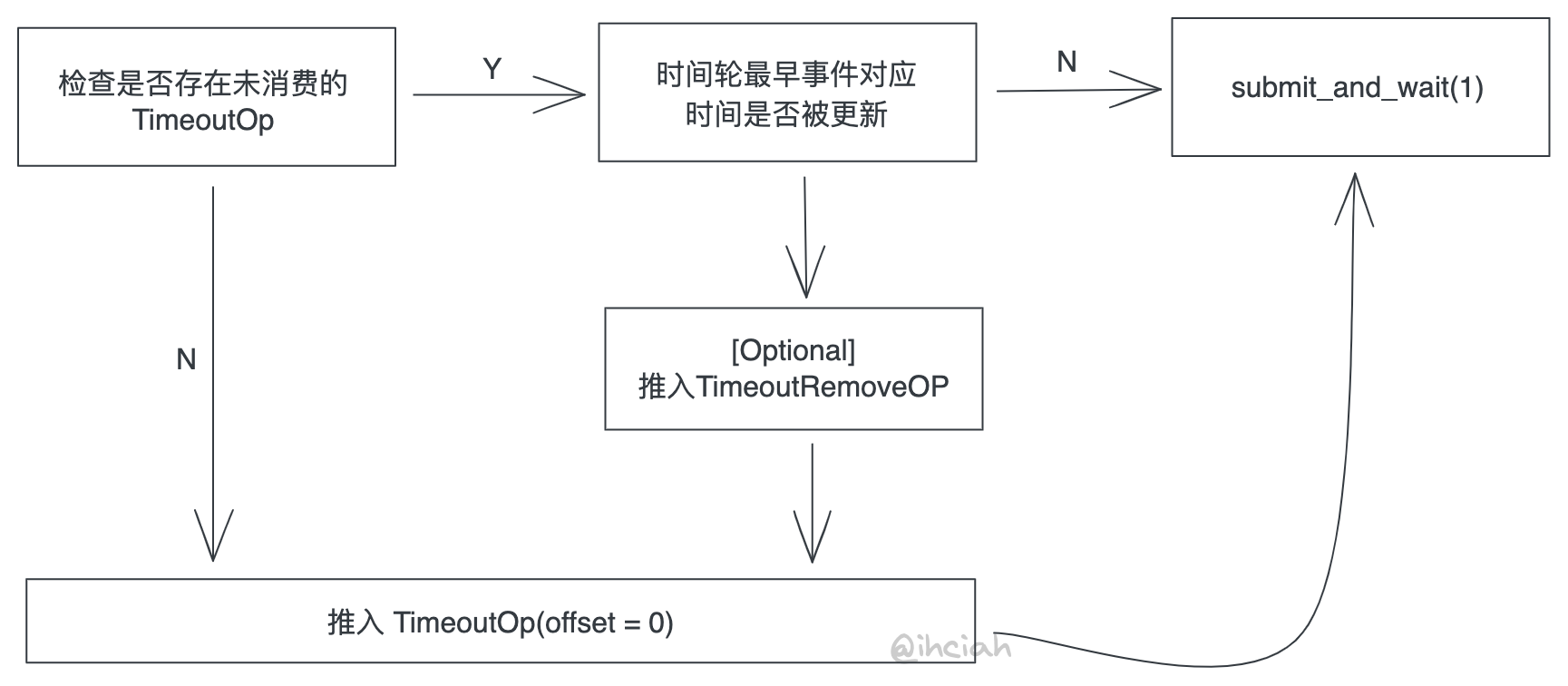
Discussion
When inserting a TimeoutOp, we should do so as late as possible because it may be cancelled. Therefore, solution 1 is not advantageous as it requires inserting two TimeoutOps and two TimeoutRemoveOps when it goes from 0->1->0->1 before wait, which is unnecessary. Solution 1 is essentially impractical.
Solution 2 and Solution 3 correspond in execution timing to Tokio and Glommio under the EPOLL scenario. The difference in detail between them is:
- Under solution 2, any CQ completion concurrently completes the TimeoutOp, so there is no need for a Remove, meaning no need for user_data maintenance, which simplifies implementation and saves the kernel processing cost of a TimeoutRemoveOp.
- The advantage of solution 3 over solution 2 is that if there are many waits, solution 2 requires pushing a TimeoutOp every time, whereas solution 3 can check whether the TimeoutOp has been consumed to save some pushing; however, the downside is that when a timeout is cancelled, a TimeoutRemove has to be pushed.
In our actual business scenarios, most of the time events are used as timeouts, with a minority for periodic polling.
In timeout scenarios, timeouts are typically set and removed, and actual timeouts are not on the hot path: so we preliminarily decide to use solution 2. Also, solution 2 is simple to implement, with a low optimization cost for future changes.
Cross-thread Communication
Although the runtime is thread per core, without cross-thread communication capabilities, many things can’t be done. For example, a common case is a single thread fetching configuration and distributing it to the thread-local storage of each thread.
If only cross-thread communication capability is needed, then no runtime support is necessary. It’s achievable either with lock-free data structures, or cross-thread locks.
But we hope to integrate this capability at the runtime level. For instance, Thread A has a channel rx, and Thread B has a tx; data is sent by B, and A can await on rx. The challenge in implementation is that the reactor on thread A may already be trapped in the kernel waiting for the uring CQ, and we need to wake up the corresponding thread when the task is woken.
Unpark Capability
Thus, we need to add an additional Unpark interface on the Driver trait for cross-thread proactive wake-up.
Under epoll, Tokio’s internal implementation is to register an eventfd. As Tokio’s scheduling model relies on cross-thread wake-up, an eventfd will be hung on epoll whether you use any of Tokio’s sync data structures or not; our implementation does not depend on this, only relying on it when using our implemented channel, so we insert the relevant code conditionally compiled with the “sync” feature, striving for zero cost.
How to insert an eventfd under io_uring? Similar to what we do in the time driver with park_timeout, we can push a ReadOp of 8 bytes directly, with the fd being that of the eventfd. Eventfd reads and writes are 8 bytes (u64).
Note: The documentation mentions two syscall flags (IORING_REGISTER_EVENTFD, IORING_REGISTER_EVENTFD_ASYNC), which are not used for this.
Ref: https://unixism.net/loti/ref-iouring/io_uring_register.html
When do we need to push eventfd? We can maintain an internal state to mark whether an eventfd already exists in the current ring. Before sleep, if it already exists, we can sleep directly; if not, we push one and mark it as existing.
When consuming CQ, if we encounter userdata corresponding to eventfd, we mark it as non-existent, so it will be re-inserted before the next sleep.
When we need to unpark a thread, we just get the corresponding eventfd and write 1u64 into it; then the fd will be readable, triggering the ring to return from the syscall.
We maintain UnparkHandle in a global Map for easy cross-thread awakening. Upon thread creation, we register a Weak reference of our UnparkHandle globally.
When cross-thread wake-up is needed, we just need to get the UnparkHandle from the global Map and try to upgrade it, and then write data. To reduce access to the entire Map, we cache this mapping within each thread.
Referring to the eventfd implementation, the kernel internally has locks and ensures that the 8-byte u64 is written in one go, avoiding disorder issues. So, the implementation has now been changed to go directly through libc::write. (wow so unsafe!)
Integration of Waker
In a pure local thread scenario, our wake-up logic is as follows:
- We want to wait for a future to execute on the local thread.
- Since the event source is uring, we store the task’s waker in the op-associated storage area when the future is polled.
- Uring generates an event and wakes the waker.
- Upon execution, the waker re-inserts the task into the local thread’s execution queue.
Under the uring driver, our event source is uring, so uring is responsible for storing and waking the waker; under the time driver, our event source is the timing wheel, so it is also responsible for storing and waking the waker.
Now our event source is from another thread. Taking the oneshot channel as an example, when rx is polled, the waker needs to be stored in the channel’s shared storage area; after tx send, the waker is fetched from the shared storage and woken. The waker’s wake-up logic is no longer simply adding the task to the local queue, but instead needs to schedule it into the queue of the thread where it belongs.
Therefore, we need to add a shared_queue to each Executor for sharing wakers that are pushed remotely. When a non-local waker is woken, it adds itself to the target thread’s queue.
Another reference implementation in Glommio:
The previously mentioned solution involves cross-thread waker transfer and can generally support structures like channel, mutex, etc.
Another approach is not to transfer the waker; instead, when polling, the waker is added to the thread’s local structures, and after the sender has data, it does not directly wake the receiver’s waker but rather directly wakes the thread it belongs to, letting the receiving thread poll all channels that have wakers.
These polling methods may not be efficient in certain scenarios and are not universally applicable.
Executor Design
Executors in a thread-per-core model should, in theory, be quite straightforward:
- Simply create a Queue, push tasks to one end, and consume tasks from the other end.
- When there are no tasks available, fall into a syscall and wait for at least one task to complete.
- After receiving a completed task, process each one systematically, apply the syscall results to the buffer, and wake the corresponding tasks.
This logic might indeed hold true for epoll; however, with io-uring, some additional optimizations may be possible.
Low Latency or Reducing syscalls
After we have enqueued the SQE, we have the option to immediately submit() to quickly complete the syscall, reducing latency; alternatively, we might wait and use submit_and_wait(1) when there’s nothing else to do. For the sake of the highest possible performance, we opt for the second approach (as do Glommio and Tokio-uring)—test data reflects that the latency is not actually high, and sometimes it can be even lower due to decreased CPU usage compared to Glommio. When the load is relatively low, a dynamic approach may be adopted to decide whether to submit more aggressively.
Starvation Issues
In this case, starvation problems are often caused by user code issues. Consider the following scenarios:
- Each time the user’s Future is
polled, it spawns a new task and then returns Ready. - The user’s Future always wakes immediately.
- The user’s Future involves too many state transitions, or there is a loop in state transitions.
If we choose to handle IO only when there are no tasks (including submission, waiting, and reaping), then the tasks that depend on IO will not be processed in these scenarios, because the task queue will never be empty or the tasks will never finish executing.
For problems 1 and 2, we proposed a solution: rather than executing all tasks, we set an execution limit and forcefully perform a submission and reaping when that limit is reached.
For problem 3, a cooperative mechanism similar to the one used in Tokio can be implemented, which limits the number of recursive poll executions, with the aim of restricting the number of state transitions.